Abstact
- 간단한 구조의 Decoder
- multi-scale feature
- Positional Encoding X
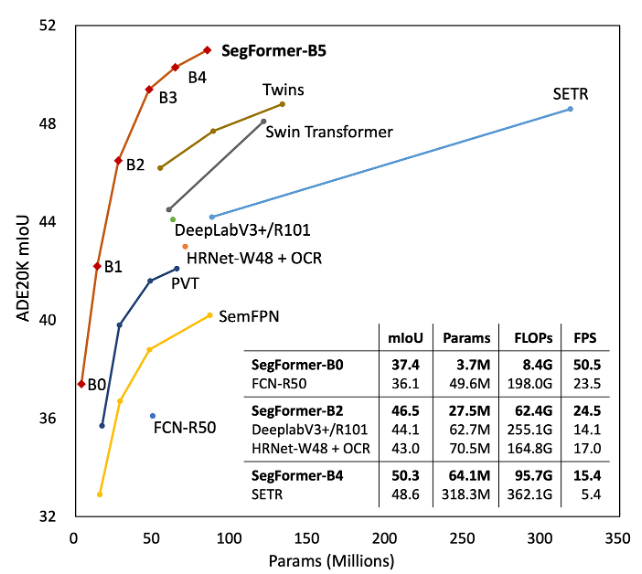
1.Introduction
- Transformer가 vision task에 쓰이며 발생하는 문제는?
=> output이 single scale의 낮은 resolution feature + large image에 대해 높은 계산량
- Encoder, Decoder 모두 redesign
=> hierachical Transformer Encoder (no positional encoding) + 간단한 Decoder (All MLP, 계산량 감소) + 효율적이고 정확
positional encoding이 사라짐에 따라 학습에 사용되지 않은 이미지 사이즈를 테스트 시 interpolation 사용으로 인한 성능 하락을 피할 수 있다.
MLP로만 이루어진 Decoder를 사용하여, 각 feature map의 local attention + multiscale feature map들을 합침으로써 얻는 global attention을 통해 강력한 representation을 보인다.
2.Relate Work
- Semantic Segmentation
- Transformer backbones
- Transformers for specific tasks
3.Method
- 입력 :H x W x 3, patch size : 4 x 4
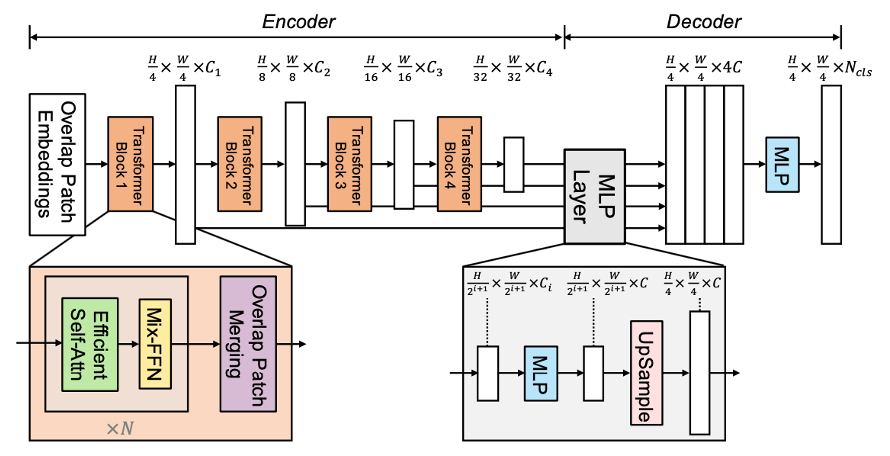
SegFormer는 두 개의 main module로 구성된다.
1. Hierarchical Transformer Encoder : high-resolution에선 coarse feature를, low-resolution에선 fine feature를 생성
2. lightweight ALL-MLP Decoder : 마지막 최종 semantic segmentation mask를 위해 multi-level feature를 합침
입력 이미지 사이즈가 H x W x 3 일때 VIT(Vision Transformer)에서는 patch size를 16 x 16으로 설정하였다.
저자들은 dense prediction task에서 더 높은 성능을 뽑기 위해 그보다 더 작은 4 x 4 patch size를 사용하였다.
이렇게 나눈 patch들은 multi-level feature map 을 뽑아내는 Transformer encoder로 들어가게 되며, 이때 각 feature map의 size는 원본 이미지에 대해 {1/4, 1/8, 1/16, 1/32}으로 설정한다.
MLP decoder에서는 multi-level feature map을 여러 레이어에 거쳐 최종적으로 H/4 x H/4 x N(class) resolution을 갖는 Segmentation mask를 예측하게 된다.
1. Hierarchical Transformer Encoder (MiT)
1-1. Hierarchical Feature Representation
: multi-level feature 생성
(high-resolution coarse feature, low-resolution fine-grained feature)
1-2. Overlapped Patch Merging

: 인접 Patch간 정보 교류가 부족
-> CNN kernel처럼 overlap하면서 Patch Merging
(stride, padding 이용)
ViT에서는 N x N x 3 patch를 1 x 1 x C 벡터로 표현하였다. 이때 각 patch들은 서로 non-overlap 상태이기 때문에 patch들 간에 local continuity 가 보존되기가 어렵다.
이를 해결하기위해 Swin Transformer에서는 Shifted Window를 통해 패치들간의 local continuity를 보존하려고 했고
SegFormer에서는 이 문제를 overlapping patch merging 으로 접근하였다.
1-3. Efficient Self-Attention
: 기존 수식은 O(N^2)의 계산 복잡도를 가짐 (N = H * W)
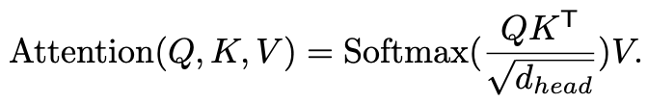
-> Reduction ratio 사용, Key와 Value의 N 감소
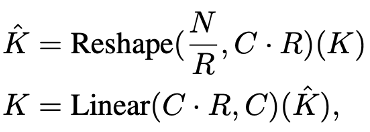
N을 R로 나누고 C에 R을 곱하면 Reshape이 가능해지고 이때 C dot R을 Linear 연산을 통해 다시 C로 줄임으로써
N/R x C차원의 Key, Value로 만들어 줄 수가 있다.
저자들은 실험을 통해 Stage-1부터 Stage-4 까지의 R을 [64, 16, 4, 1]로 설정
1-4. Mix-FFN
ViT에서는 지역 정보를 추가하기 위해 positional encoding을 적용시켰다.
하지만 이런 방식은 input resolution이 고정되어야 한다는 문제가 있으며 이는 input resolution이 달라지게 되면 interpolation을 통해 크기를 맞춰줘야 해서 성능 하락을 유발한다.
이에 저자들은 positional encoding이 semantic segmentation에 꼭 필요한 것은 아니라고 하며 positional encoding을 대신하여 3 x 3 Convolution (stride: 1 / padding: 1)을 FFN에 적용시켰다. (3 x 3 Conv의 zero padding을 통해 leak location의 정보를 고려할 수 있다고 주장)
실험을 통해 3 x 3 convolution이 충분히 Transformer에 위치 정보를 제공할 수 있다는 것을 보였고 파라미터 수를 줄이기 위해 3x3 convolution을 depth-wise convolution으로 사용하였다.
: positional embedding 대신 3 x 3 Convolution (zero padding)
(3x3 depth wise convolution)
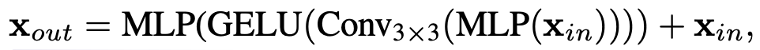
depth wise convolution이란? 동일 channel 내에서만 convolution 연산 수행
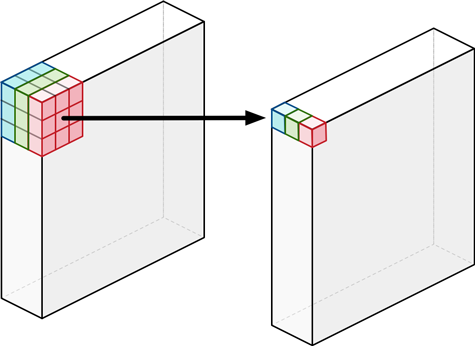
= 필터 수는 입력 채널의 수와 동일
2. Lightweight All-MLP Decoder
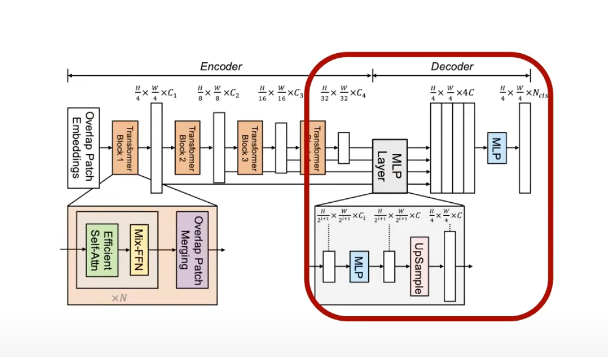
1. multi-level feature들의 channel을 모두 C로 동일하게 통합
2. feature size를 original image의 1/4 크기로 Upsample
3. feature들을 concatenate and 4배로 증가한 channel을 C로 복원
4. 최종 segmentation mask를 예측
(batch x N(num of class) x H/4 x W/4)
위 1-4번을 식으로 표현하면 아래와 같다.
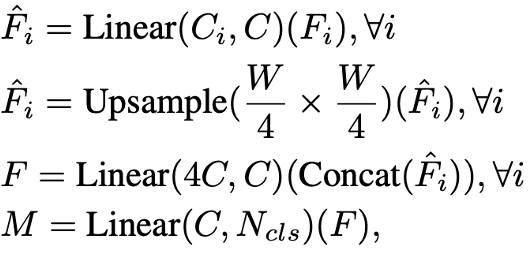
3. Effective Receptive Field Analysis (ERF Analysis)
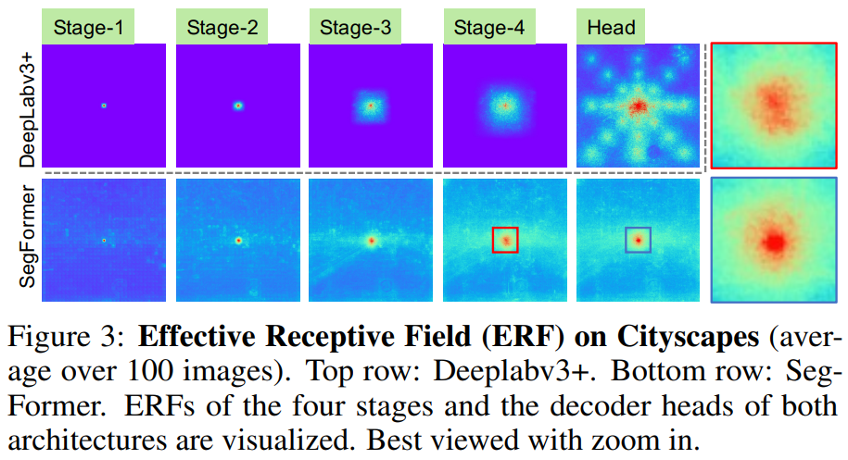
Semantic Segmentation 에서는 context 정보를 포함하도록 큰 receptive field 를 유지하는 것은 핵심 문제이다.
DeepLabv3+의 ERF는 가장 깊은 stage-4 에서도 상대적으로 작고,
SegFormer의 Encoder는 하위 stage에서 local attention을 자연스럽게 생성하는 동시에 stage-4 에서 context를 효과적으로 캡처하는 non-local attention 을 출력할 수 있습니다.
또한 줌인 패치(맨 오른쪽)에서 볼 수 있듯이 Decoder의 MLP head(파란색 상자)의 ERF는 stage-4(빨간색 상자)와 다르며 non-local attention 보다 local-attention이 더 강합니다.
저자는 SegFormer의 Decoder 설계가 non-local attention을 활용하고 복잡하지 않으면서 더 큰 receptive field를 가진다고 설명합니다.
또한 SegFormer 의 Decoder 디자인은 본질적으로 local / non-local attention 을 모두 생성하는 트랜스포머의 이점을 취합니다.
4.Experiment
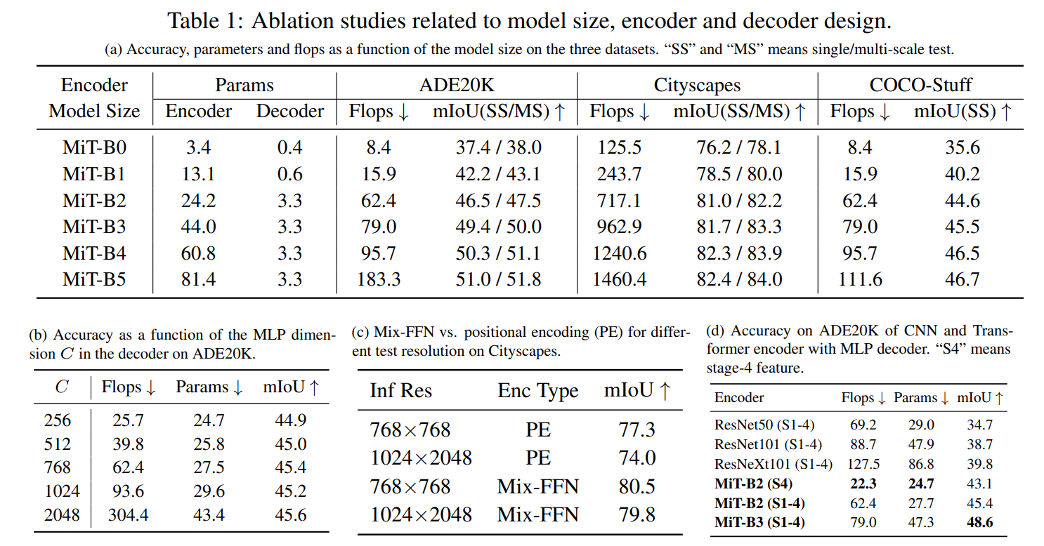
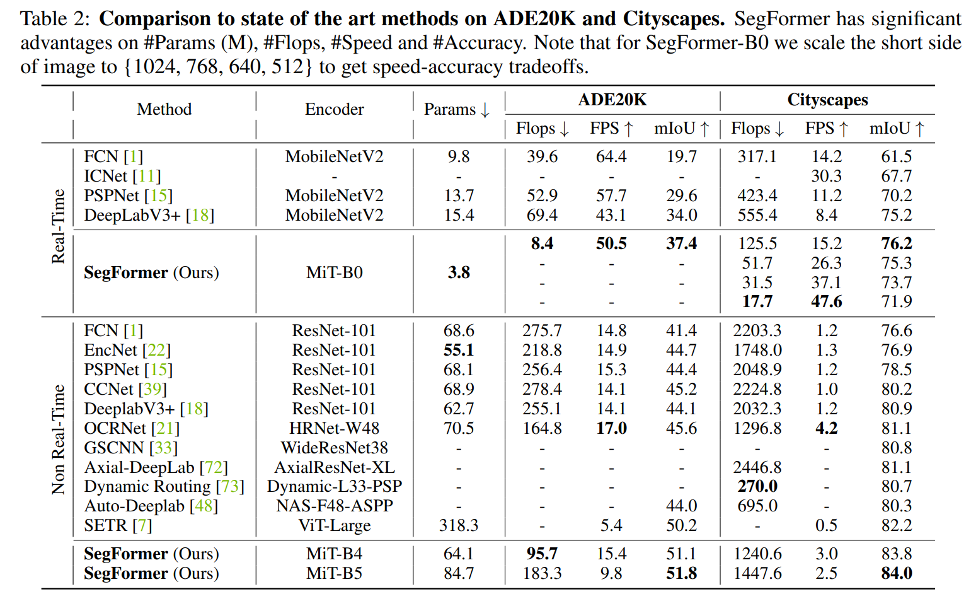
5.Conclusion
복잡한 디자인을 가지는 기존의 방법을 피하고 efficiency하면서 좋은 performance을 보여준다.
여러 Dataset에서 SOTA를 달성했다.