
Introduction
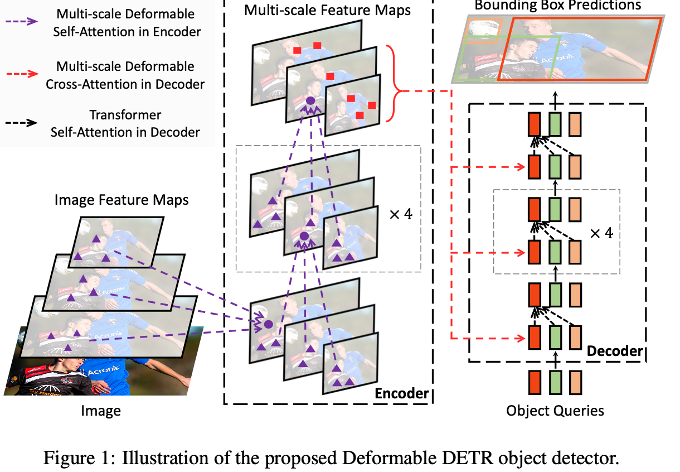
- DETR의 후속작이다.
- 느린 수렴(Convergence)과 작은 물체에 대한 낮은 성능에 대한 대안
- multi scale feature 사용
- deformable attention module 사용
Attention weight가 uniform하게 초기화되고 나서, 의미있는 위치에 focus 시키기 위해 학습하는 시간이 매우 길다.
(uniform이란, 평균이 0이고 분산이 1인 분포)
ex) key가 160개라면, 1/160으로 시작해서 gradient도 매우 작은 상태, query가 주어졌을 때 key는 이미지의 다른 모든 pixel이 되기 때문에 학습이 오래 걸림
+
작은 객체를 detection은 주로 high resolution feature map에서 이뤄지는데, Encoder는 feature size의 제곱에 비례한 시간복잡도를 가지기 때문에, high resolution image를 감당할 수 없음-> 작은 물체 탐지 성능 저하
또한 resnet(backbone)에서 나온 마지막 feature map을 사용하는데, 이는 low resolution 이미지이므로 작은 물체에 대한 탐지 능력이 부족함
deformable convolution에서 영감을 받아왔다고 한다.
Related Work
- Efficient Attention Mechanism
- Multi-scale Feature Representation for Object Detection
위 두 가지 방법을 참고했다고 한다.
특히 Deformable DETR은 Deformable Conv Network (DCN)으로부터 영감을 얻었다.
일반적인 Convolution 연산은 고정된 크기의 kernel을 기반으로 수행되지만 deformable convolution은 feature를 특정 layer에 통과시켜 Sampling point를 예측한 후, 해당 point를 기반으로 convolution 연산을 수행한다.
특정 위치의 object들에 맞추어 sampling이 이루어지면서 고정된 크기의 kernel로부터 오는 한계점을 극복할 수 있다.
=> 큰 물체에 대한 탐지 능력 향상
Loss는 DETR과 동일하다.
Revisiting Transformer and DETR
1. Multi head attention
=> query, key 쌍의 attention 정도 = attention weight
MHA는 attention weight를 각각의 key와 융합하는 것을 의미한다. 이는 다양한 관점에서 상관관계를 보기 위함이라고 한다.
(query : 질문용 단어)
(key : 문장 안의 모든 단어, query를 key의 모든 단어에 모두 질문하는 방식)
2. DETR
- Encoder’s MHA : q,k 모두 feature map의 pixel
- Decoder’s MHA : cross-attention
- Loss : 동일
CNN의 backbone(=ResNet)에서 추출한 feature map을 encoder의 input으로 사용
cross-attention이란, MHA와 deformable attention 둘 다 연산하는 것
Deformable Attention - Encoder,Decoder
1. Encoder
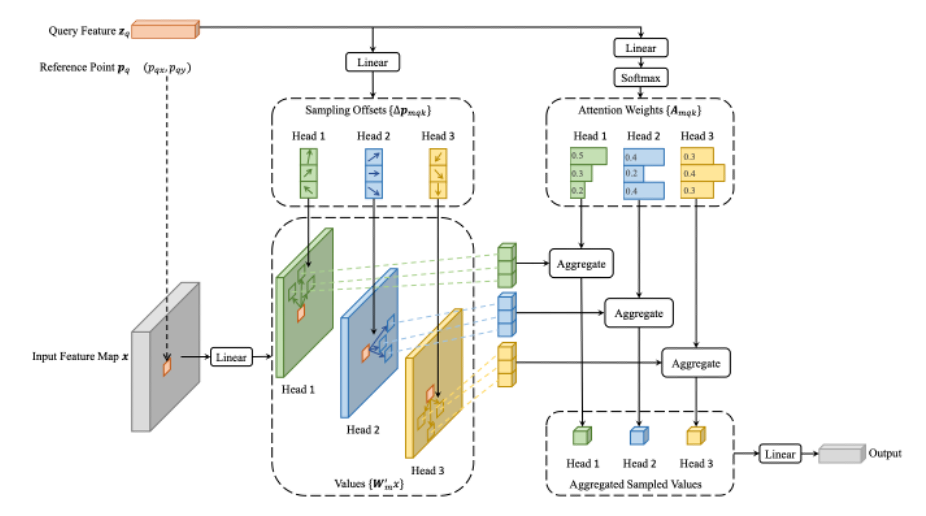
reference point란, feature안의 어떠한 한 기준점에서 offset을 얼마나 설정해서 attention을 해야 하는지를 결정하는 기준점이다.
encoder의 경우, reference point가 input query(=feature map의 모든 pixel)와 동일하다.
input feature map x의 특정 쿼리의 위치에서 독립적인 linear layer를 거친 후,
query feature을 또 다른 linear layer를 통과시켜 sampling offset을 얻고,
위 두 방법의 결과물을 통해 sampling points들을 얻는다.
그 후, sampling points들을 통해 feature들을 뽑게 된다(그림에서 세로 블럭들)
그리고 query feature를 또 다른 linear layer에 통과시켜 얻은 attention weight와 feature를 aggregate하여 value를 얻는다.

detr의 경우, 한 위치에서 모든 픽셀에 대해 attention 연산을 수행하는 반면,
deformable detr은 한 위치에서 sampling points들에 대해서만 attention 연산을 수행함. 또한 하나의 scale이 아닌, 다른 모든 scale에서의 pixel에 대해서도 attention 연산 수행하므로 속도와 여러 크기의 물체에 대해 이득!(이 때 좌표를 0-1 사이 값으로 normalize)
2. Decoder
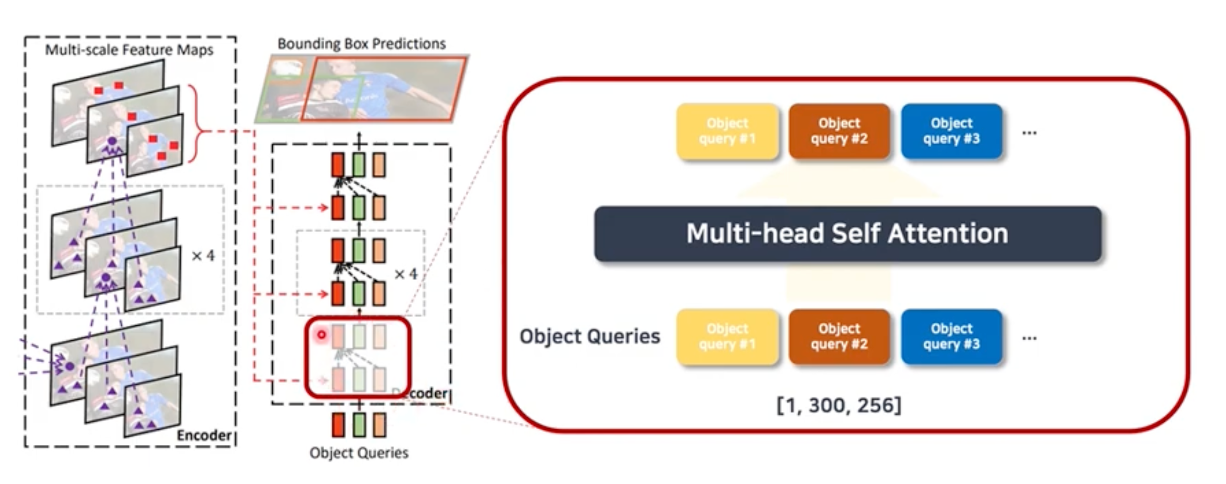
decoder의 경우, self attention부분과 cross attention하는 부분이 존재한다.
self attention은 decoder의 input인 object queries들을 multi head attention하는 부분이고 (기존 DETR과 동일)
cross attention은 object queries들을 linear layer에 통과시켜 reference points들을 추출하고, 각 reference point에서 sampling points를 뽑아 인코더와 동일한 방식으로 value를 계산하는 부분이다.
Method
1. Deformable Attention Module


2. Multi scale Deformable Attention Module

multi-scale의 feature map을 이용하는 것 이외에 큰 차이는 없다. 다만, 앞서 reference point 좌표값을 0-1 사이로 normalize 했기에 이를 해당 feature map에 맞게 rescale해주는 부분이 존재한다.
3. Deformable Transformer Encoder
- Input : multi-scale feature map, 1x1 conv 연산을 통해 동일한 차원으로 변환된다.
= input과 output은 동일한 resolution을 가지게 된다!
그리고 위에서 언급되었던 multi-scale deformable attention module을 통해 진행함
- 기존 Transformer Encoder의 Attention 방식을 multi-scale deformable attention module로 변환
4. Deformable Transformer Decoder
- cross-attention, self-attention module로 구성, self attention은 기존의 MHA를 그대로 사용하지만 cross-attention은 multi-scale deformable attention module을 사용한다
Experiments


DETR보다 성능, 시간적인 면에서 향상됨을 확인할 수 있다.
효율적이고 빠르게 수렴하는 end-to-end object detector이다.
multi-scale feature map을 이용해서 작은 물체 검출에도 유용하다.
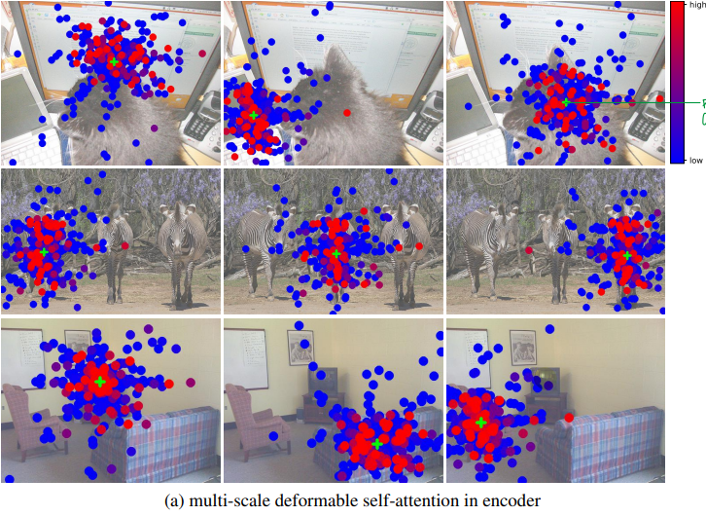
Visualization

'AI 논문 공부' 카테고리의 다른 글
| EfficientDet : Scalable and Efficient Object Detection Review (2020) 논문 리뷰 (0) | 2023.05.22 |
|---|---|
| EfficientNet : Rethinking Model Scaling for Convolutional Neural Networks 논문 리뷰 (1) | 2023.05.12 |
| Yolo v3 논문 리뷰 (0) | 2023.04.25 |
| DeiT : Training Data-efficient Image Transformers & Distillation through Attention 논문 리뷰 (0) | 2023.04.13 |
| DETR : End-to-End Object Detection with Transformers 논문 리뷰 (1) | 2023.04.07 |