EfficientNet의 후속작인 EfficientDet에 대해 리뷰하겠습니다. 혹시 EfficientNet을 읽어보지 않으셨거나, 기억이 안나시면 제 블로그에 있으니 찾아보시는 걸 추천 드립니다.
0.Abstact

- SOTA detectors become too expensive
- model efficiency becomes more important
- both accuracy and efficiency
논문의 저자들은 SOTA 모델이 너무 비싸다, 모델의 efficiency 역시 중요하다. 정확도와 효율성 모두 잡은 모델은 없을까 고민하다가
EfficientDet을 고안해냈다.
1. Introduction
- Question : Is it possible to build a detection architecture with both higher accuracy and better efficiency across a wide spectrum of resource constraints?
앞서 말한 것처럼, 한정된 자원에서 높은 정확도와 효율성을 모두 잡을 모델을 만드는 것은 불가능할까?
- Two Challenges
1. Efficient multi-scale feature fusion
= 보통 CNN은 width와 height가 줄어들면서 feature의 abstraction level이 올라간다. 다양한 level의 feature를 섞어서 operation 후 연산하는 구조가 기존에 많이 있었다. (예를 들어 FPN, PANet, NAS-FPN 등등)
기존에는 다양한 scale의 feature map을 사이즈만 맞춰준 뒤, sum 연산을 진행하였는데, sum만으로는 부족하다고 논문의 저자들은 생각하였다.
2. Model Scaling
= 보통 작은 모델에서 점점 큰 모델로 키워나가는 방식인데, EfficientNet에서 했던 것처럼 compound scaling을 진행 하였다. (resolution, depth, width 세가지를 적절히 scaling하는 방식)
=> EfficientNet backbone + BiFPN + Compound scaling == EfficientDet
2. Related work
- One stage detector
- Multi-Scale Feature Representations
- Model Scaling
EfficientDet은 one-stage detector이고, BiFPN 방식을 적용했으며, 새로운 compound scaling 방식을 적용했다.
3. BiFPN
3-1. Problem Formulation


feature pyramid 구조에서 사용할 feature map을 Pin 벡터로 정의, Pin 벡터들을 넣었을 때 좋은 feature map output이 나오도록 하는 transformation 함수 f를 찾는 것이 목표이다. (goal : find a transformation f )

Pin 벡터들은 level 3~ 7의 feature level을 가지는데, 각각 resolution이 input image의 1/2^i 이다. 예를 들어, input image가 640x640일 때, Pin level3의 resolution은 640 / 2^3 = 80x80이다.
위 그림은 다음과 같은 수식으로 연산된다

3-2. Cross-Scale Connections
- PANet(Pyramid Aggregation Net) adds an extra bottom-up path
- NAS-FPN employs NN search to search for better cross-scale feature network topology

PANet은 FPN 구조에 bottom-up path를 추가하였다.
NAS_FPN은 neural network가 스스로 FPN 구조를 찾도록 만든 것이다. 그러나 엄청난 GPU 시간을 필요로 하고, 그 구조가 매우 어렵고 불규칙적이다.
PANet을 좀 더 알아보자면,

앞서 말했듯, PANet은 FPN 구조에 bottom-up path를 추가한 구조이다.
왜? 입력 이미지와 가까운 feature map에서 작은 물체를 탐지한다. 그런데 abstraction level이 낮아서 성능이 좋지 못하다.
그래서 FPN 구조에서는 top-down 방식을 통해 abstraction level이 높은 feature map과 합쳐지면 괜찮을거라 생각하였다.
PANet 저자들은 입력이미지와 가까운 feature map의 장점(위치 정보를 많이 가지고 있음)을 살리고 싶어, 위치 정보를 약 10 layer의 bottom-up 구조로 올렸고, 실제로 꽤 괜찮은 성능을 보였다고 한다.
NAS-FPN에 대해 좀 더 알아보자면, 구조는 다음과 같다.

다시 돌아와서,
- PANet achieves better accuracy then FPN, NAS-FPN but, use Simplified PANet (removing those nodes that only
have one input edges with no feature fusion) and, adding extra edge from original input to output if they are at the same level
PANet이 FPN이나, NAS FPN보다 성능이 더 좋아서 이 방식을 채택했는데, 약간 간소화된 PANet 구조를 사용했다.
simplified PANet에서 알 수 있듯, fusion이 없는 node들을 지웠는데 왜 그랬냐면 fusion이 없다면 그냥 conv 연산 또는 아무 연산이 일어나지 않는다. 결국 fusion을 하는 node가 아니면, FPN 구조에서 역할이 없을 것이라 판단하여 삭제하였다고 한다.


결국엔 simplified PANet에서 edge가 더 추가된 BiFPN 구조를 사용하였다.
BiFPN에서는 추가적인 엣지를 하나 더 사용했는데, 이유는 더 많은 fusion을 할수록 성능이 좋아지니까 input node를 가져다 사용한 것이라고 한다.
=> 더 많은 feature를 fusion할 수 있게 되어 성능이 더 향상되었다.
- repeat the same layer
또한, 점선 박스로 된 구조를 3개 정도 이어서 사용하였다.
BiFPN의 수식은 다음과 같다.

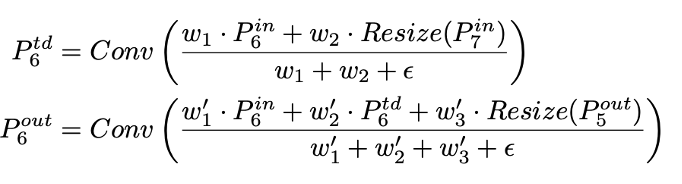
3-3. Weighted Feature Fusion
1. Unbounded fusion
: just weight * layer

2. Softmax-Based Fusion
: apply to softmax to weighted sum, but, leads to slowdown GPU

3. Fast Normalized Fusion
: weight / (sum all weights + epsilon), 분자 Wi는 ReLU func에 의해 >=0 임을 보장받는다.

실제로 논문의 저자들은 3번 방법을 사용했다고 한다. 2번 방법과 성능차이가 없는데, 30%가량 빨라서 사용했다고 한다.
4. Architecture
1. Architecture

- pre-trained EfficientNet
- weights are shared (=> BiFPN에서 Class/box pred layer로 넘어갈 때 보이는 점선들은 실제 어떤 layer가 존재하는 것이 아니라, 가중치들이 전부 공유되기 때문에 다음과 같이 표현한 것이다.)
2. Compound Scaling
compound scaling에 관한 내용은 EfficientNet 참조!
- backbone, BiFPN, class/box network, resolution에 모두 compound scaling 을 진행

- heuristic scaling 진행( 논문의 저자들은 scaling할게 너무 많아서 어쩔 수 없이 휴리스틱한 방법을 이용했다고 함)
backbone : same EfficientNet
BiFPN : Width = 64 * 1.35^Φ, Depth = 2 + Φ
class/box prediction : Width = 64 * 1.35^Φ,
Depth box/class = 3 + int(Φ/3)
resolution : 512 + Φ * 128 (because level 7, ½^7)
수식은 다음과 같다.


연산량은 layer수에 비례 + 채널의 제곱에 비례 + resolution의 제곱에 비례하기 때문에 다음과 같은 수식이 도출된다.
결국, 전체 연산량은 2^Φ 에 비례한다.
5. Experiment

D0 ~ D7은 백본, 인풋 사이즈, scaling의 차이이다.
Ratio를 보면 1x가 기준이고, 예를 들어 yolo v3의 FLOPS는 28x인데 이는 EfficientDet-D0의 연산량이 1/28 이라는 의미이다.
