2020년 Facebook AI에서 ECCV에 발표한 논문이다.
Abstract
- NMS, anchor box 등을 삭제하여 복잡한 detection pipeline을 간소화하였습니다.
- ‘bipartite matching’ 을 사용했습니다. 자세한 설명은 뒤에서 하도록 하겠습니다.
- object detection을 direct set prediction으로 생각했다고 합니다. 아래 그림과 같습니다.
- set안에는 class 정보와 bounding box에 대한 정보가 존재합니다.

Introduction
- 기존 방식은 많은 바운딩 박스를 만들어, 그것들의 subset을 추리고, 그 다음에 subset을 regression(refine)하는 방식으로 진행하였습니다.
- 이때 사용되는 NMS이나 anchor box는 이해 및 구현이 어렵고, 코드가 길어지는 단점이 존재합니다.
이에 따라, 해당 논문의 저자들은 direct set problem이라는 개념을 소개합니다.

The DETR Model
1. DETR 구조
- CNN
- set of image features
- transformer encoder-decoder
- set of box predictions
- bipartite matching

이미지를 CNN에 넣으면 feature들이 추출됩니다. 그것들을 transformer에 넣으면 set of box predictions이 추출되고, 이 추출된 것들을 정답 박스들과 1대1 매칭을 하는 과정입니다.
위 그림에서는 검정,파랑,갈색 박스는 no object와 매칭되었습니다.
[빨강, 노랑, 초록] 박스는 객체를 예측했는데, 이때 오른쪽 정답 그림과 1대1 매칭을 진행하여 [빨강, 노랑] 박스는 정답과 매칭이 되고, 초록 박스는 no object와 매칭이 된다.
2. Set prediction
- N개의 고정된 prediction box를 사용합니다. (N은 클래스 개수보다 더 크게 설정해야 함! -> 이미지에 몇개의 클래스가 존재할지 모르므로 넉넉하게 크게 설정해주자)

- Y는 ground-truth, Y hat은 N개의 prediction box입니다.
- 이미지 안에 ground-truth(=Y)도 N개로 맞춰줘야합니다! 이때 공집합(no object) 이용하는데, DETR이 객체 N개를 예측하지만 이미지 안에는 N개의 클래스가 없을 수 있기 때문에, 공집합(no obj) 을 padding 해줘서 사용합니다.
* 1대1 매칭을 하기 때문에 중복이 생기지 않아 NMS를 사용하지 않아도 된다고 합니다!
3. Set prediction Loss

- set prediction시 사용되는 loss입니다. 정답과 예측 박스들을 1대1 매칭하게 되는데, 이때 헝가리안 알고리즘을 사용합니다.
(헝가리안 알고리즘이란 assignment 알고리즘으로, 예를 들어, N명의 사람이 N개의 일을 할 때, 최소(또는 최대) 비용으로 어떤 사람에게 어떤 일을 맡기는지를 결정하는 알고리즘이다. brute force 방식이라고 이해하면 될 것 같습니다.)
- 헝가리안 알고리즘으로 나온 cost를 L match로 지정해주었습니다.
- 시그마 기호는 박스들의 순서를 의미하므로, 1번 식은 L match의 cost가 최소가 되는 예측 박스들의 순서를 의미합니다. 즉, 정답이랑 매칭하는 순서를 정하는 것입니다!
- ci는 target class label이고, bi는 바운딩박스 정보로 박스의 x,y,w,h를 의미합니다. (x,y는 박스의 center, h,w는 박스의 높이와 너비)
- 2번식의 앞부분은 클래스가 no object이 아닐 때, 그 클래스가 맞을 확률을 곱해줍니다. 음수를 취하는 이유는 loss값이기 때문에 확률이 높을 수록 값이 작아야하기 때문입니다. 그리고 바운딩 박스에 대한 loss를 더해서 Lmatch를 완성합니다. bounding box loss는 뒤에서 더 설명하겠습니다
4. Loss function

- 네트워크 학습에 사용되는 loss입니다. negative log-likelihood를 사용했습니다.
- 만약 클래스가 no object라면, 10을 나눠주어서 class imbalance 문제를 예방하였다고 합니다.
(class imbalance란, 간단히 말해서 객체가 없는 곳에 만들어지는 박스가 더 많은 문제를 의미합니다.)
5. Bounding box Loss

다른 알고리즘에서는 anchor box라는 pre defined된 candidate가 있고, 그것들을 얼마나 움직일 지에 대한 델타를 학습하는 방식을 이용했는데, detr은 박스를 직접 예측합니다.
위 과정에서 약간의 손해가 발생하는데, 이것을 L1 loss로 방지하고자 하였습니다.
그러나 L1 loss의 특성 상, 큰 박스에 대해서 더 큰 loss를 내기 때문에 (거리의 차를 구하기 때문) 이를 보완하고자 generalized IoU loss를 추가해서 사용했습니다
람다 iou와 람다 L1을 통해 각각 적당한 가중치도 부여했습니다.
6. Overall Architecture of DETR

cnn 거쳐서 나온 feature들을 transformer에 넣기 위해서, positional encoding을 추가했습니다 (=위치정보 추가)
object queries는 박스가 N개이므로 N개가 되어야 합니다. 초기엔 0값이지만 추후 학습이 되며, decoder의 positional encoding을 추가해주는 역할도 합니다
마지막으로 3 layer짜리 feedward network를 거쳐 예측하게 됩니다.
- backbone
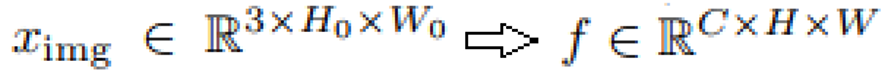

height, width, rgb의 이미지가 cnn을 통과하면 channel * h * w로 바뀝니다. (첫번째 식)
논문의 저자들은 backbone으로 resnet을 사용했기 때문에 channel은 resnet의 최종 채널 수인 2048이 되고, h,w는 보통 cnn을 거치면 2^5만큼 줄어들기 때문에 32로 나눠주었다고 합니다.
- Encoder

Encoder로 들어가기 전, 1x1 conv를 통해 c보다 작은 d로 채널 감소해줍니다.
그리고 Encoder에 들어가려면, 입력이 vector로 바뀌어야 하기 때문에 3차원을 2차원으로 변경해줘야합니다.
= > d * hw 꼴로 바꿔줍니다 = d size의 h*w개 벡터로 변형
또한 attention 기법은 순서를 고려하지 않으므로, 앞서 말했듯, positional encoding을 추가해야 합니다.
positional encoding은 feature와 elemental-wise 연산을 하므로, d차원이어야 합니다. 이때 x축, y축 따로 주고싶어서 d/2차원으로 설정했다고 합니다.
- Decoder
Encoder의 parallel한 출력이 decoder에 들어갑니다.
decoder 역시 permutation-invariant 하기 때문에, 위치 정보 추가가 필요하고, decoder에 Input으로 들어가는 것들은 값이 다 달라야 다른 결과를 얻을 수 있습니다! (=출력 predicion이 1대1 매칭하기 때문 !)
object queries가 위 역할을 해줍니다.
- Difference with original
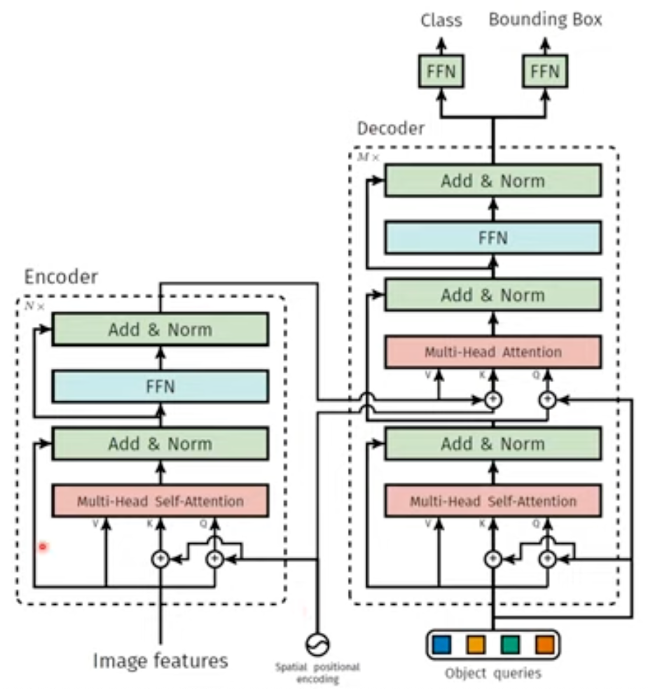
positional encoding과 object queries 가 매 layer마다 계속 들어갑니다
또한 auxiliary decoding loss를 사용하여 성능을 높였다고 하는데, 이는 decoder에서 매 layer마다 FFN에서 매번 결과를 뽑아서 다양한 loss를 통해 학습하는 것을 의미합니다.
Experiment

큰 객체에서는 우세한 결과를 보였지만, 작은 객체에서는 성능이 떨어졌습니다.
CNN은 local하게 이미지를 보지만, Transformer는 모든 포지션, 즉 전체 이미지를 보기 때문에 큰 이미지에 강세를 보이기 때문입니다.
반면, 구조상 최종 레이어에서 나오는 피쳐를 사용하기 때문에, 작은 이미지에 대한 정보가 많이 사라집니다.
논문의 저자들도 이를 숙제로 남겨놨습니다. FPN과 같은 구조를 도입하면 개선이 되지않을까라고 생각합니다.
추후 나온 deformable DETR에서 이런 단점을 많이 개선했다고 한다
Conclusion
- 장점
- Transformer를 detection에 처음 적용
- 준수한 정확도와 성능
- End to End training이 가능
- 간단하고 깔끔한 코드
- 단점
- 학습하는데 오랜 시간
- small object detection 성능 떨어짐
'AI 논문 공부' 카테고리의 다른 글
| Yolo v3 논문 리뷰 (0) | 2023.04.25 |
|---|---|
| DeiT : Training Data-efficient Image Transformers & Distillation through Attention 논문 리뷰 (0) | 2023.04.13 |
| ViT 논문 리뷰 (AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE) (0) | 2023.03.27 |
| Attention Is All You Need(2017) 논문 리뷰 (0) | 2023.03.16 |
| You Only Look Once:Unified, Real-Time Object Detection (YOLO) 논문 리뷰 (0) | 2023.02.14 |