
ViT 논문을 읽기 전, Attention Is All You Need와 같은 transformer 구조에 관한 논문을 읽고 오시는 걸 추천드립니다.
0. Abstract
그동안 NLP분야에선 transformer 구조가 굉장히 지배적인 standard 였습니다
사실, vision 분야에서의 응용은 잘 되지 않았습니다.
하지만! 새로 등장한 Vision Transformer는 기존의 다른 CNN들에 비해 계산량은 상당히 적으면서도 성능은 좋았습니다
CNN 구조 대부분을 Transformer로 대체했다는 특징이 존재합니다.
단, 많은 데이터를 pre-train해야한다는 제약이자 단점이 존재합니다.
1. Introduction
- self-Attention을 적용하려는 시도가 많았지만 현대의 하드웨어 가속기에는 비효율적이었습니다. 그래서 결국 transformer 구조를 그대로 적용하게 되었습니다.
transformer의 구조의 장점으로는 계산이 효율적이며, 확장성이 좋습니다.
즉, 데이터 셋이 크면 클수록 모델을 크게 해도 성능이 포화되지 않고, 커질수록 성능도 향상됩니다.
transformer를 computer vision처럼 적용하는 방법은 이미지를 Patch로 분할 후 Sequence로 입력하는 것입니다.
특징으로는, 모든 경우를 고려할 수 있을만큼 거대한 데이터셋으로 학습할 경우 굉장히 우수한 성능을 보인다는 것입니다.
반면, Cnn이 가지는 Locality와 Translation Equivariance 같은 특징들이 없기 때문에, inductive bias가 존재하지 않습니다.
(inductive bias는 만나보지 못한 상황에 대한 추가적인 가정을 의미합니다.)
cnn은 지역적인 정보를 많이 활용하고, 트랜스포머는 모든 정보를 활용합니다, 즉 global한 정보는 transformer가 좋지만 cnn은 전제적인 큰 영역보다 특정 범위에 대한 지식이 뛰어나기 때문에 주어지지 않은 샘플들에 대해서도 학습을 잘 할 수 있습니다.
transformer는 이미지들이 적을 때 그 효과가 강하지 못합니다. 그래서 대규모 데이터 셋을 이용합니다!
대규모 데이터를 이용시 이러한 inductive bias 부재의 문제를 해결가능함을 확인할 수 있습니다.
2. Related Work
Transformer 종류 : GPT, BERT

3. Method
3-1) Vision transformer

transformer 는 이미지를 텍스트 sequence처럼 사용하는 구조입니다.
우선, 이미지를 고정된 크기의 patch로 나눠주고,
각각의 patch를 linearly embedding, positional embedding 하여 인코더에 input 합니다.
( positional embedding이란, 단어의 위치정보(=어순) 입력 )
여기에 classification token을 추가하여 해당 이미지가 어떤 이미지인지 알려주는 과정을 추가합니다.
classification token은 해당 정보를 이용하여 이미지 class를 예측하도록 하는 역할을 합니다.
3-2) Linear Projection of Flattened Patches

transformer의 input은 1차원 시퀸스입니다.
따라서 앞서 고정된 크기의 patch로 나눠준 이미지를 1차원으로 flattened해야 합니다.
수식으로 표현하면, H x W x C 형식의 이미지를 N x (P x P x C)로 변환해야 합니다.
H는 이미지의 높이, W는 이미지의 넓이, C는 이미지 채널입니다. N은 시퀀스 수, P x P는 이미지를 나누는 고정된 patch의 크기입니다.
즉, 이미지를 N개의 1-Dimension 벡터로 만들어주고 이렇게 1차원으로 바꾼 이미지를, Transformer에 사용할 수 있는 D size의 백터로 바꿔줍니다. (논문에서는 D size를 변경해가며 실험함)
이걸로 우리는 Transformer Input 형식에 맞춰서, 이미지를 바꿨습니다.

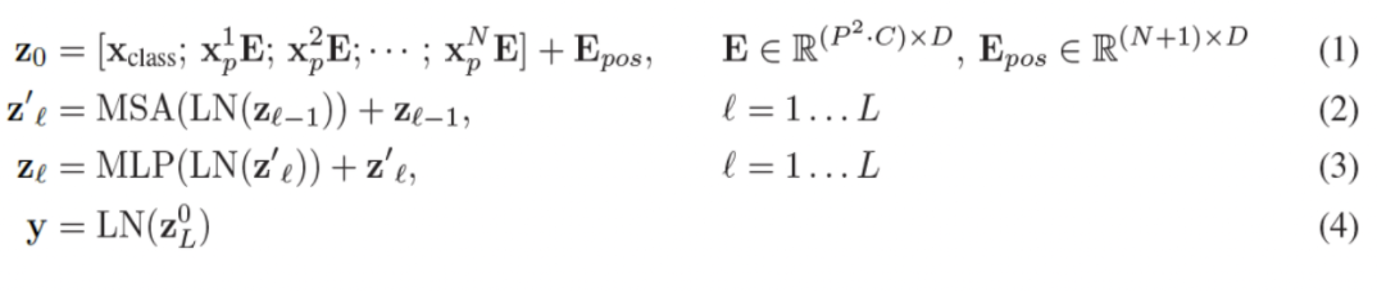
(1): 입력에 해당하는 수식입니다. Xclass는 classification token(=class 정보)입니다

-> patch로 나눈 N개의 이미지 시퀀스입니다
마지막 Epos는 각각 시퀀스의 순서를 나타내는 Positional Encoding입니다. (앞서 말씀드렸듯, positional embedding은 위치 정보를 유지하기 위해 추가해줍니다)
(2) : Transformer에 해당하는 수식입니다.
이전 입력 값에 Layer Normalization한 후에, Multi-head Attention을 적용합니다. 해당 값을 skip connection을 해줍니다.
LN이나 MHA 등등은 Attention Is All You Need 논문 정리에 있으니 참고하시길 바랍니다.
skip connection이란, ResNet의 Residual 같은 개념입니다!
(3) : MLP head에 해당하는 수식입니다. 이전 입력 값에 Layer Normalization한 후에, Transformer에서 나온 값을 MLP합니다
(4) : 마무리로 나온 학습 Class를 찾습니다. 이러한 형태의 layer가 x개 존재한다고 할 때, 위 과정을 x번 반복하여 결과를 도출합니다.
ZL은 마지막 차원을 의미합니다.
3-3)Fine Tuning and Higher resolution
공개된 모델을 fine-tuning하여 사용하는 것이 좋다고 합니다.
Fine tuning을 진행할 땐 MLP head 를 제거하고, pre-training prediction head를 붙여야 한다고 합니다
pre-training prediction head이란, 0으로 초기화한 D*K 차원의 feedforward layer를 연결하여 사용합니다 (= single linear layer)
(이때 k는 풀고자 하는 task의 class 개수)
이러한 방식으로 fine tuning을 진행하는 이유는 방대한 양의 pre-training 이미지가 필요하기 때문입니다
참고로 파인 튜닝 시, pre training에 사용된 이미지보다 높은 해상도의 이미지를 쓰는 것이 좋다고 합니다
높은 해상도를 사용하면, patch의 크기가 동일할 때 더 큰 시퀀스를 사용할 수 있기 때문입니다 (= N이 증가 = 입력이 증가)
4. Experiments
앞서 말씀드렸듯, D 사이즈는 Model의 크기마다 다름을 알 수 있습니다.
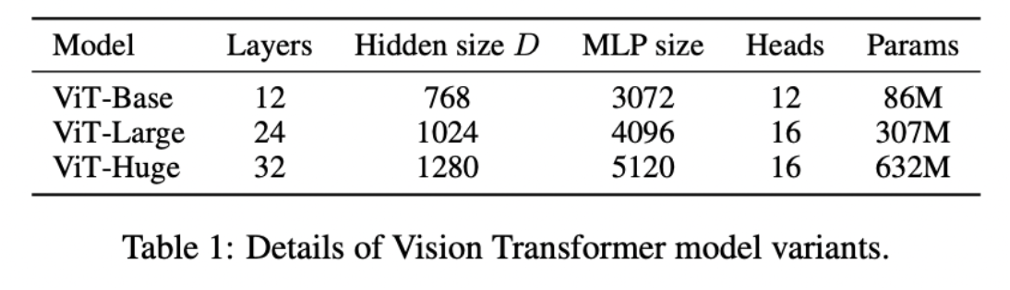

14, 16은 patch 사이즈를 의미합니다
5. Conclusion
다른 cnn 모델들보다 더 적은 cost로 더 좋은 성능을 보입니다.
약간의 전제조건이 있는데, 대량의 데이터로 pre-trained된 모델에 원하는 데이터 셋으로 fine tuning 할 때 더 좋은 성능을 보입니다
다만, 데이터 셋이 작다면 train하기 어렵다는 단점이 존재합니다
cv분야에 transformer를 적용했다는 엄청 큰 의의를 가집니다.
'AI 논문 공부' 카테고리의 다른 글
| DeiT : Training Data-efficient Image Transformers & Distillation through Attention 논문 리뷰 (0) | 2023.04.13 |
|---|---|
| DETR : End-to-End Object Detection with Transformers 논문 리뷰 (1) | 2023.04.07 |
| Attention Is All You Need(2017) 논문 리뷰 (0) | 2023.03.16 |
| You Only Look Once:Unified, Real-Time Object Detection (YOLO) 논문 리뷰 (0) | 2023.02.14 |
| FPN : Feature Pyramid Net 논문 리뷰 (0) | 2023.02.06 |