
목차
0. Abstract
1. Feature Pyramid
2. Pyramid
3. FPN
4. Bottom-Up pathway
5. Top-Down pathway and Lateral connections
6. Application
7. Experiments and Conclusion
Abstract
등장 배경?
- 다양한 크기의 객체 인식 필요
- 기존 방식은 많은 메모리와 엄청난 양의 연산을 통해 이루어짐 => 여러 방면에서 상당히 비효율적
- 이를 개선하고자 나타난 방식이 FPN
(기존 방식은 아래에서 소개하도록 하겠습니다)
Feature Pyramid
- 기존 방식 (a) : input image의 크기를 다양하게 resize하고 네트워크에 입력하는 방법
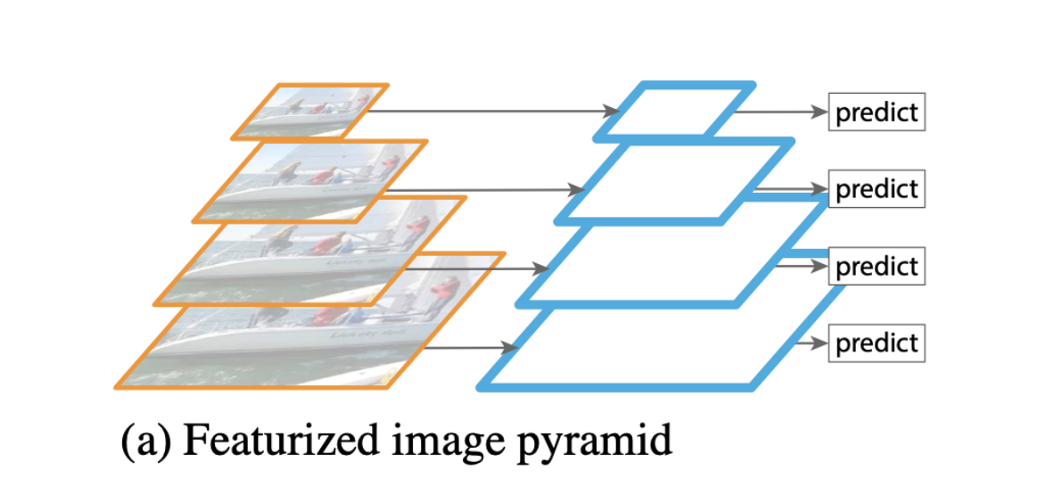
장점 : 다양한 크기의 객체를 포착하는데 좋은 결과
단점 : 연산량이 많아 추론 속도가 느리며, 메모리를 엄청 잡아먹음 -> 사용x
- 기존 방식 (b) : input image를 네트워크에 입력하여 최종 feature map에서 object detection
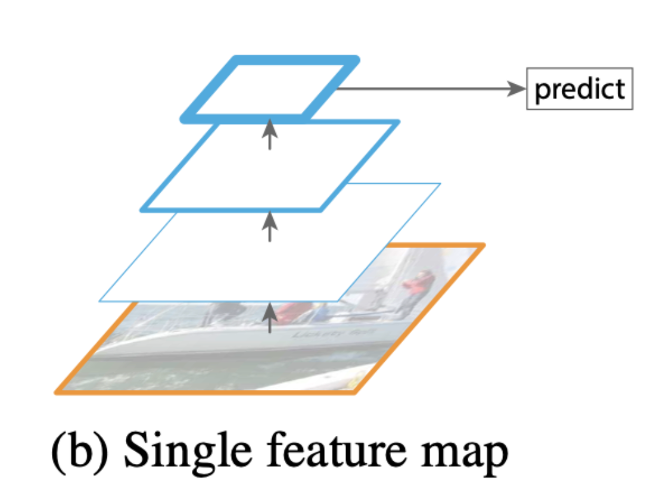
특징 : yolo v1에서 이러한 방법을 사용함, 한번에 특징 압축하여 마지막에 압축된 특징만을 사용
장점 : (a) 방법보다 적은 연산량
단점 : (a) 방법보다 떨어지는 성능, multi scale x
- 기존 방식 (c) : CNN 신경망을 통과하는 중간 과정에 생성되는 feature map 각각에 Object Detection을 수행
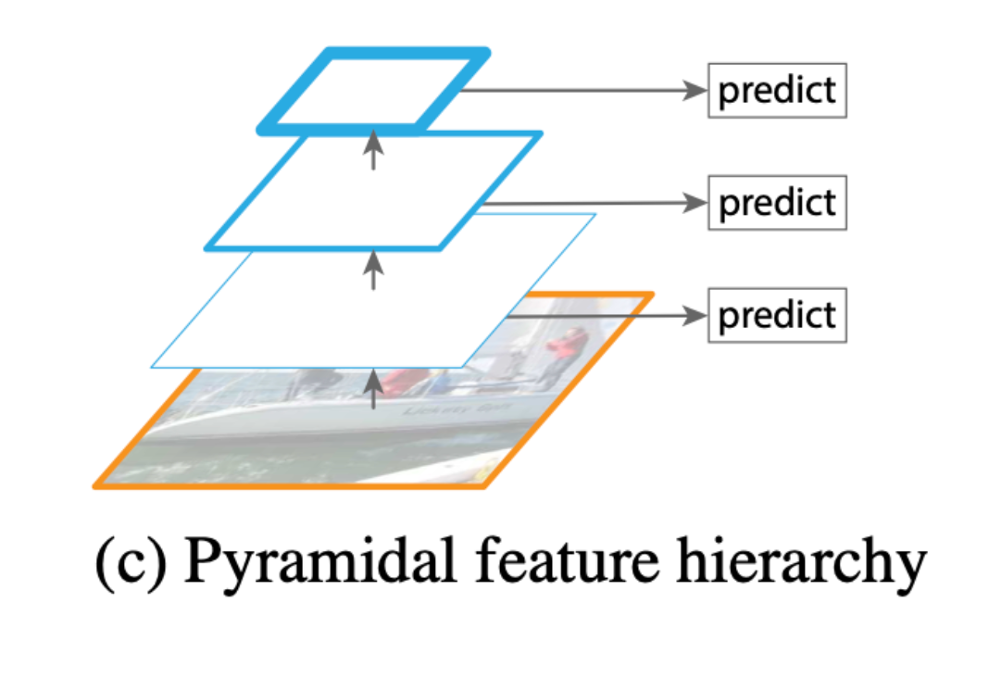
특징 : SSD가 이러한 기법에 속하며, 얕은 layer에서 추출한 feature map에서 저수준 특징(low-level feature)까지 학습하면 representational capacity를 손상시켜 객체 인식률이 낮아진다.
SSD는 문제를 해결하기 위해 low-level feature를 사용하지 않고, 전체 convolutional network 중간 지점부터 feature map을 추출,
하지만 FPN논문의 저자는 높은 해상도(=low level)의 feature map은 작은 객체를 detect할 때 유용하기 때문에 이를 사용하지 않는 것이 적절하지 않다고 지적하였다.
(*representational capacity 는 머신러닝 모델의 flexibility, 즉 실제 데이터의 적응력 정도를 의미)
장점 : 작은 물체에 대한 정보를 살리면서 Object Detection을 수행할 수 있다.
단점 : 상위 레이어에서 얻게 되는 추상화 된 정보를 활용하지 못하는 단점
Pyramid
- pyramid란, 네트워크에서 얻을 수 있는 서로 다른 해상도의 feature map을 쌓아올린 형태

- Convolutional network에서 더 얕은, 즉 입력층에 보다 가까울 수록 feature map은 높은 해상도(high resolution)을 가지며, 가장자리 곡선 등과 같은 저수준 특징(low-level feature)을 보유하고 있음
- 반대로 더 깊은 layer에서 얻을 수 있는 feature map은 낮은 해상도(low resolution)을 가지며, 질감과 물체의 일부분 등 class를 추론할 수 있는 고수준 특징(high level feature)을 가지고 있음
- Object Detection 모델은 Pyramid의 각 level의 feature map을 일부 혹은 전부 사용하여 예측을 수행
FPN
-Architecture
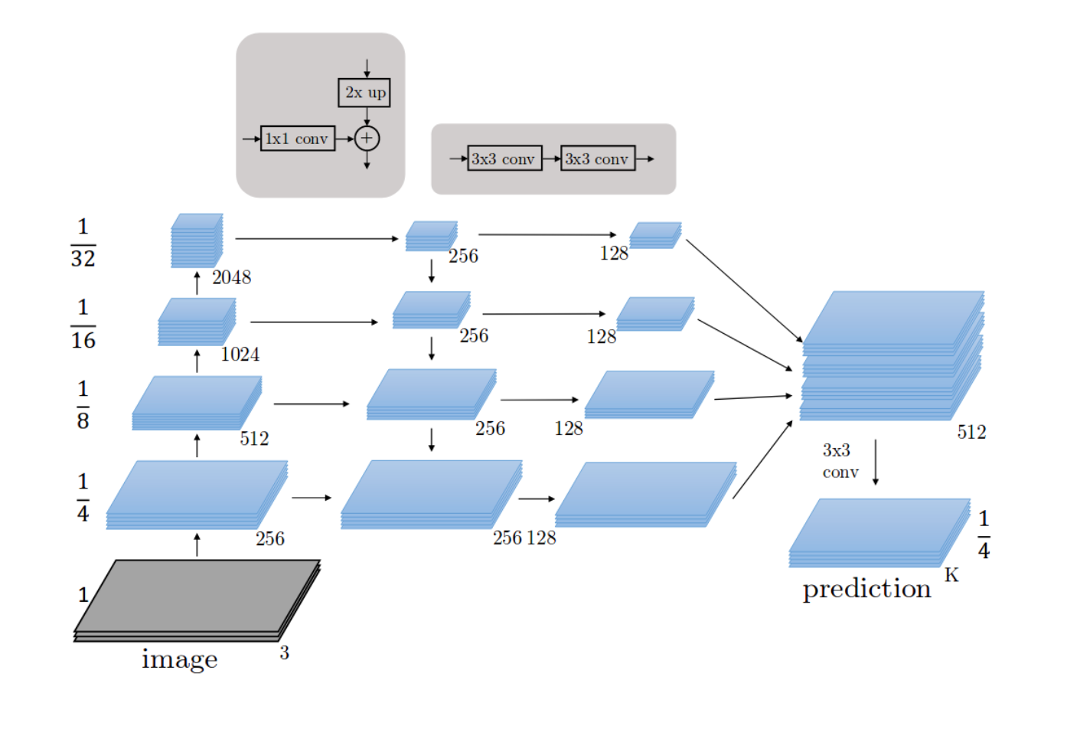
- fpn은 single-scale 이미지를 convolutional network에 입력하여, 다양한 scale의 feature map을 출력하는 네크워크
- 논문에서는 backbone network로 resnet을 사용함
- 논문에서는 fpn 구조를 2가지의 pathway로 나눠 설명함
1. bottom-up : resolution(해상도)을 줄여가며 feature를 얻는 forward과정
2. top-down : low resolution이지만 feature를 다시 원래 resolution으로 내려주면서 기존의 feature와 결합한다.
Bottom-Up pathway
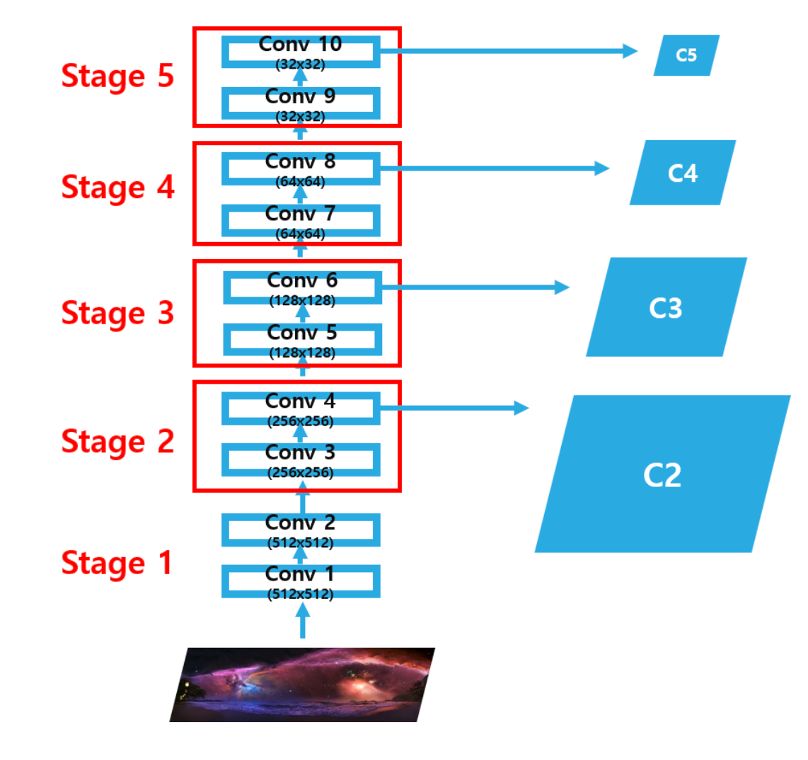
- Bottom-up pathway 과정은 Image를 convolutional network에 입력하여 크기가 2배씩 작아지는 feature map을 추출하는 과정이다.
(512->256->128->64->32)
- 이 때 각 stage의 마지막 layer의 output feature map을 추출 -> C2, C3, C4, C5
- 네트워크에는 같은 크기의 feature map을 출력하는 layer가 많지만 논문에서는 이러한 layer를 모두 같은 stage에 속해있다고 정의한다.
각 stage별로 마지막 layer를 pyramid level로 지정하는 이유는 stage 내에서 더 깊은 layer일수록 더 강력한 feature를 보유하고 있기 때문
- ResNet의 경우 각 stage의 마지막 residual block의 output feature map을 활용하여 feature pyramid를 구성
- 추출된 output feature map은 그림에서 conv4, conv6, conv8, conv10의 output feature map을 의미하며, 각각 [4,8,16,32]의 strid를 가지고 있다. 여기서 [C2,C3,C4,C5] 은 각기 원본 이미지의 1/4, 1/8, 1/16, 1/32 크기를 가진 feature map이다.
- conv2의 output feature map의 경우 너무 많은 메모리를 차지하여 제외하였다고 한다
Top-Down pathway and Lateral connections
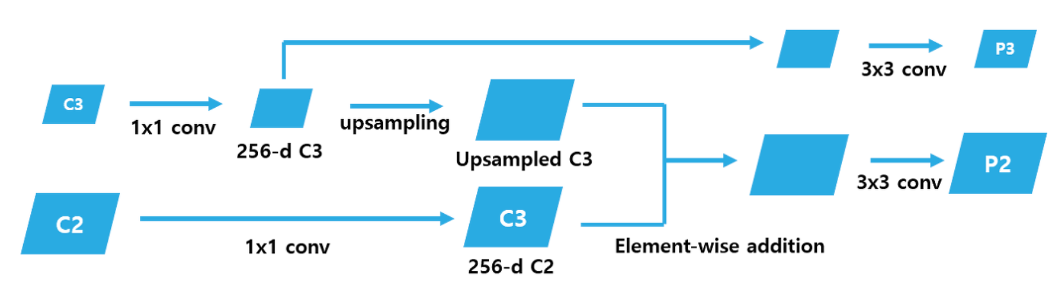
- Top-down pathway는 각 Pyramid level에 있는 Feature map(c2,c3 등등)을 2배로 Upsampling하고 Channel 수를 동일하게 맞춰주는 과정이다.
- 각 pyramid level의 feature map을 2배로 upsampling 해주면 바로 아래 level의 feature map과 크기가 같아진다. c3를 upsampling 하면 c2와 크기가 같아진다.
- 이 때 nearest neighbor upsampling 방식을 사용한다. 이때 모든 pyramid level의 feature map에 1x1 conv 연산을 적용하여 channel을 256으로 맞춘다. (아래에 추가 설명)
- 그 다음 upsample된 feature map과 바로 아래 level의 feature map과 element-wise addition 연산을 하는 Lateral connections 과정을 수행한다.
- 이후 각각의 feature map (사진에서 오른쪽 2번째에 위치한 파란색 박스들) 에 3x3 conv 연산을 적용하여 feature map을 얻는다. 이때 얻은 feature map은 각각 {p2,p3,p4,p5}이다. 이는 각각 {c2,c3,c4,c5} feature map의 크기와 같다.
가장 높은 level에 있는 feature map c2의 경우 1x1 conv 연산 후 그대로 출력하여 p2를 얻는다. 이 과정을 통해 4개의 서로 다른 Scale을 가진 Feature map을 얻는다
장점
1. 단일 크기의 이미지를 모델에 입력하기 때문에 기존 방식 (a) 방식에 비해 빠르고 메모리를 덜 차지
2. multi-scale feature map을 출력하기 때문에 (b) 방식보다 더 높은 detection 성능
3. Detection 시 고해상도 feature map은 low-level feature를 가지지만 객체의 위치에 대한 정보를 상대적으로 정확하게 보존하고 있다. 이는 저해상도 feature map에 비해 downsample된 수가 적기 때문. 이러한 고해상도 feature map의 특징을 element-wise addition을 통해 저해상도 feature map에 전달하기 때문에 (c)에 비해 작은 객체를 더 잘 detect합니다.
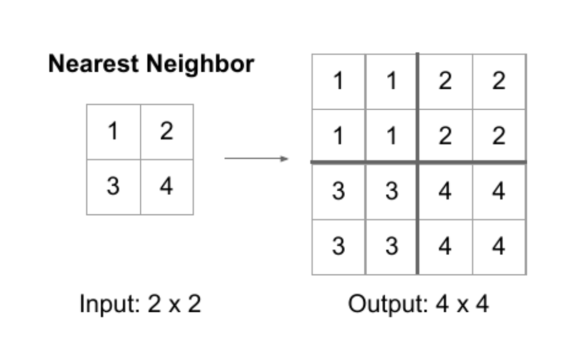
Nearest Neighbor는 Dense 데이터를 그대로 늘려서, 빈 구역에 채워 넣는 방법이다. upsampling에도 다양한 기법들이 있지만 저자들은 단순함을 위해 위 기법을 채택했다고 한다.
Application
Training ResNet + Faster R-CNN with FPN
- RPN이 적용된 Faster-R은 single이 아닌 multi-scale feature map을 사용하기 때문에 region proposal을 어떤 scale의 feature map과 매칭시킬지 결정 필요
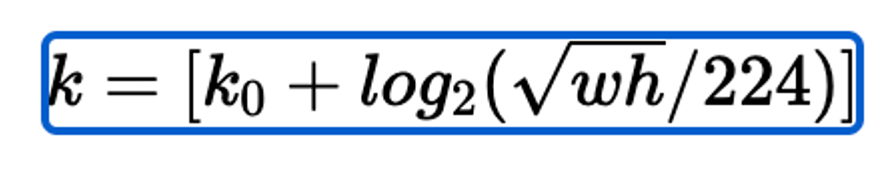
k : 피쳐맵 번호, RoI의 넓이 w, 높이 h로 k를 결정
224 : 백본이 224x224를 학습하기 때문
k zero : ROI가 들어왔을 때 매핑시킬 피쳐맵 번호를 결정하는 변수, 논문에선 4로 설정 (만약 512 512 크기의 ROI가 들어올시, 4+log2(2.28) = 5.xx 이므로 P5로 매핑됨)
- Input : multi-scale feature map {p2, p3, p4, p5} and 1000 region proposals
Experiments && Conclusion
데이터 : 80 category의 COCO-detection dataset 사용
backbone : ImageNet1k classification dataset으로 pre-train된 ResNet-50 또는 ResNet-101
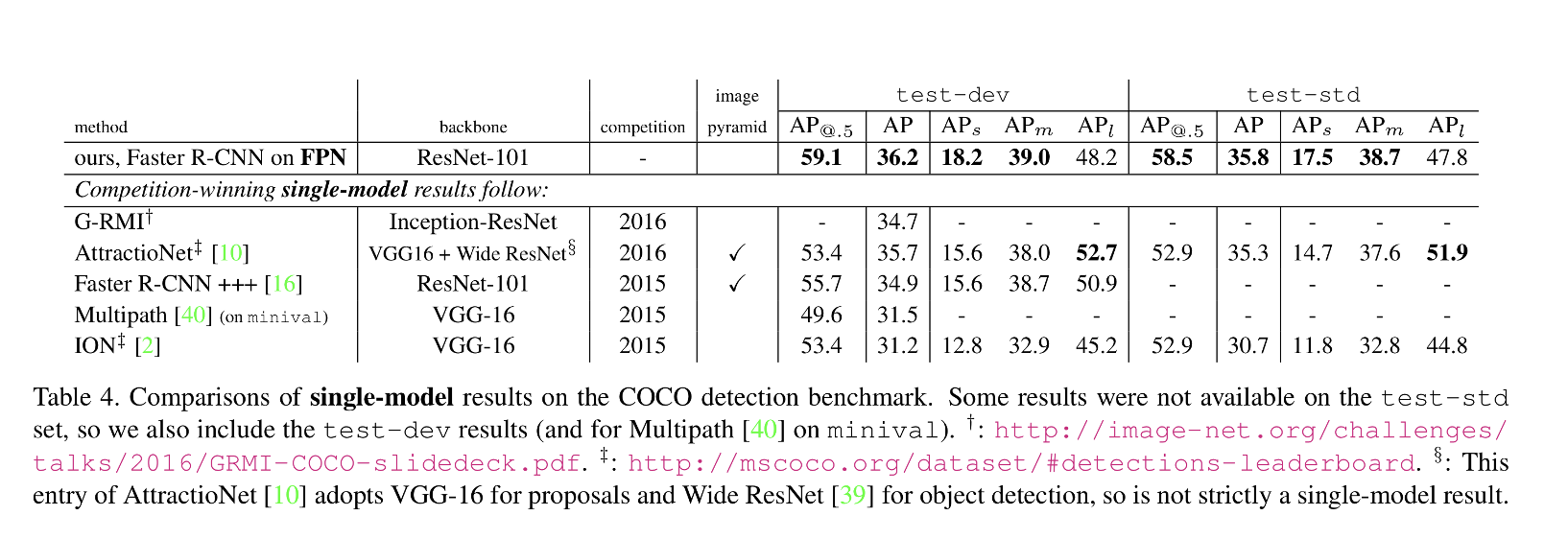
ResNet을 backbone network로 사용한 Faster R-CNN에 FPN을 결합시켰을 때, FPN을 사용하지 않았을 때보다 AP 값이 향상되었음을 확인할 수 있다. 이외에도 FPN은 end-to-end로 학습이 가능하며, 학습 및 테스트 시간이 일정하여 메모리 사용량이 적다는 장점
네트워크층이 얕은 layer의 feature map은 low-level이지만 localization에 유리한 feature를 보유하고 있는 반면, 깊은 layer의 feature map은 localization에 대한 정보는 적지만 class를 추론할 수 있는 high-level feature를 가지고 있는데, 논문에서는 이러한 feature map에 대한 특성을 파악하여 두 종류의 feature map의 장점을 모두 활용할 수 있는 좋은 해결책을 제시하였음
'AI 논문 공부' 카테고리의 다른 글
| Attention Is All You Need(2017) 논문 리뷰 (0) | 2023.03.16 |
|---|---|
| You Only Look Once:Unified, Real-Time Object Detection (YOLO) 논문 리뷰 (0) | 2023.02.14 |
| R-CNN, Fast R-CNN, Faster R-CNN 논문 리뷰 (1) | 2023.01.27 |
| Deformable Convolutional Network (DCN) 논문 리뷰 (0) | 2023.01.13 |
| resnet 논문 리뷰 (1) | 2023.01.07 |