목차
0. Abstract
1. Introduction
2. Unified Detection
3. Network Design
4. Loss
5. Limitations of YOLO
6. Result
Abstract
- 2-stage Detector
: localization과 classification 두 과정을 거쳐 객체를 Detection 함

장점 : 정확도
단점 : 느린 속도
- 1-stage Detecor
: 논문에서는 두 과정을 한번에 처리하는 방법을 제시하여 fps(초당 처리하는 frame 수)를 더욱 빠르게 하였다고 함

Introduction

- YOLO v1은 localization과 classification을 하나의 문제로 정의하여 network가 동시에 두 task를 수행하도록 설계함
이를 위해 이미지를 지정한 grid로 나누고, 각 grid cell이 한번에 bounding box와 class 정보라는 2가지 정답을 도출하도록 만들었다.
- 독자적인 Convolutional Network인 DarkNet을 도입,
이를 통해 얻은 feature map을 활용하여 자체적으로 정의한 regression loss를 통해 전체 모델을 학습시켰다
의의
1. 빠른 속도로 인해 실시간 detection이 가능해짐
2. 전체 이미지를 이용해 class 예측 -> 배경 이미지에 대한 오류 감소
3. end-to-end 학습이 가능함 ( 분류와 예측을 동시에 하므로)
Unified Detection
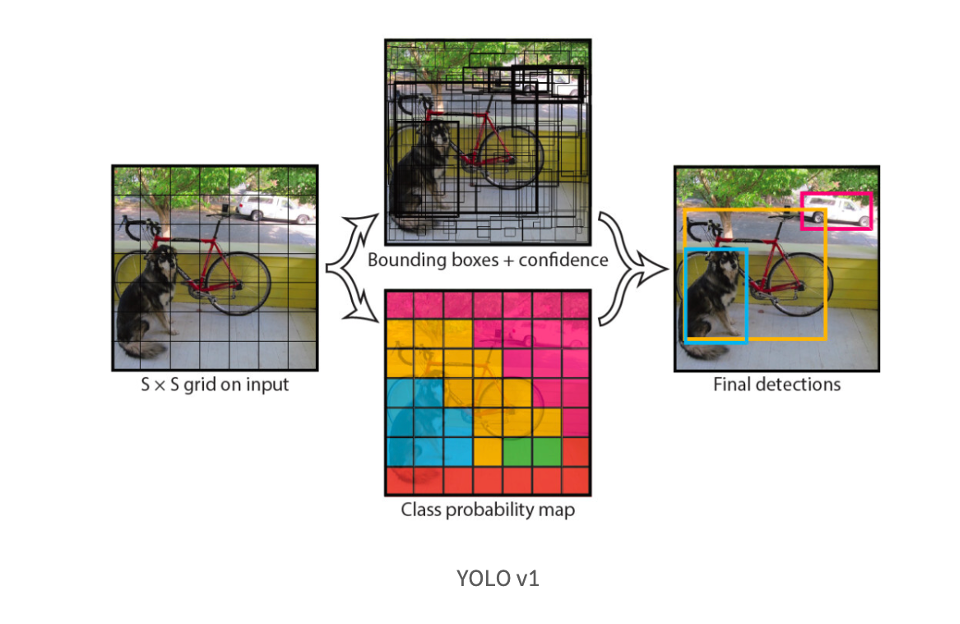

1. 입력 이미지를 SxS grid로 분할( 논문에서 S는 7)
객체의 중심이 grid cell의 중심에 들어와 있으면 해당 grid는 그 객체 detect를 담당 (=오른쪽 사진에서 빨간 점이 객체의 중심, 이 빨간 점을 포함하는 grid는 객체 detect하도록 할당) (= 4행 3열의 grid cell이 왼쪽의 개를 예측하도록 할당되었고, 4행 4열의 grid cell이 오른쪽의 개를 예측하도록 할당
이는 곧 나머지 grid cell은 객체를 예측하는데 참여할 수 없음을 의미한다.
2. 각 grid cell은 B개의 bounding box와 이 box들의 confidence score를 예측 (B는 논문에서 2로 설정)
(confidence score란 box가 object를 담고 있는지 없는지, 있다면 얼마나 잘 겹치게 bounding 하고 있는지를 반영하는 score)
논문에서 score는 Pr(Object) * IOU로 정의하고 있다. cell에 객체가 없다면 Pr은 0, 있다면 1이 된다. 즉, box안에 object가 없다면 score는 0이 되고, 있다면 IOU와 곱해져서 confidence는 IOU가 된다.
IOU란? 정답 박스와 예측 박스가 얼마나 겹치는 지를 표시

이어서,,


3) 각각의 bounding box는 box의 좌표 정보(x, y, w, h)와 confidence score라는 5개의 예측값을 가집니다.
- 여기서 (x, y)는 grid cell의 경계에 비례한 box의 중심 좌표를 의미합니다. 박스의 높이와 너비 역시 grid cell에 비례한 값입니다.
주의할 점은 x, y는 grid cell 내에 위치하기에 0~1 사이의 값을 가지지만 객체의 크기가 grid cell의 크기보다 더 클 수 있기 때문에 width, height 값은 1 이상의 값을 가질 수 있습니다.
하나의 bounding box는 하나의 객체만을 예측하며, 하나의 grid cell은 하나의 bounding box를 학습에 사용합니다.
예를 들어 grid cell별로 B개의 bounding box를 예측한다고 할 때, confidence score가 가장 높은 1개의 bounding box만 학습에 사용하는 것입니다.
4) 각 grid cell은 C개의 conditional class probabilities인 Pr(Class i|Object) 를 예측합니다. 이는 특정 grid cell에 객체가 존재한다고 가정했을 때, 특정 class i일 확률인 조건부 확률값입니다. bounding box 수와 상관없이 하나의 grid cell마다 하나의 조건부 확률을 예측합니다. 여기서 짚고 넘어갈 점은 bounding box별로 class probabilities를 예측하는 것이 아니라 grid cell별로 예측한다는 것입니다.
논문에서는 S=7, B=2, C=20 설정하였습니다. (PASCAL VOC 데이터셋을 사용하여 학습하였기에 class의 수가 20개)
즉, 이미지를 7x7 grid로 나누고 각 grid cell은 2개의 bounding box와 해당 box의 confidence score, 그리고 C개의 class probabilities를 예측합니다. 즉 이미지별 예측값의 크기는 7x7x(2x5+20)입니다. (5는 x y w h confidence를 의미) 이와 같은 과정을 통해 bounding box의 위치와 크기, 그리고 class에 대한 정보를 동시에 예측하는 것이 가능해집니다. 그리고 non-max supression을 거쳐 최종 bbox를 선정합니다.
Network Design

- YOLO v1 모델은 앞서 살펴본 최종 예측값의 크기인 7x7x30에 맞는 feature map을 생성하기 위해 DarkNet이라는 독자적인 Convolutional Network을 설계하였습니다. (DarkNet은 ImageNet 데이터셋을 통해 학습!)
- 학습 결과 GoogLeNet 모델과 비슷한 top-5 88% 정도의 정확도를 보입니다.
- YOLO는 24개의 convolutional layer와 2개의 fully connected layer로 이루어져 있습니다. 그리고 GoogLeNet에서 영향을 받아 1x1 차원 감소 layer 뒤에 3x3 convolutional layer를 이용합니다.
- YOLO는 convolutional layer로 이미지로부터 특징을 추출하고, FC layer로 바운딩박스와 class 확률을 예측합니다.
- 또한 classification task를 위해 학습시켰을 때는 224x224 크기의 이미지를 사용한 반면, detection task를 위한 학습 시에는 이미지의 크기를 키워 448x448 크기의 이미지를 사용한다고 합니다. 이는 detection task는 결이 고운(fine grained) 시각 정보를 필요로 하기 때문이라고 설명합니다.
Loss

기존 R-CNN 계열의 모델이 classification, localization task에 맞게 서로 다른 loss function을 사용했던 것과 달리 YOLO v1 모델은 regression 시 주로 사용되는 SSE(Sum Squared Error)를 사용합니다. 위의 그림에서 볼 수 있듯이 Localization loss, Confidence loss, Classification loss의 합으로 구성되어 있습니다.
1. localization loss
객체를 포함하는 cell에 가중치를 두는 파라미터, 논문에서는 5로 설정
- S2 : grid cell의 수= 49
- B : grid별 bbox의 개수 = 2
- 1 obj i,j : i번째 grid cell의 j번째 bbox가 객체를 예측하도록 할당 받으면(=객체를 포함하고 있으면) 1, 아니면 0
- xi, yi, wi, hi : round truth box의 x, y 좌표와 width, height. 여기서 크기가 큰 bounding box의 작은 오류가 크기가 작은 bounding box의 오류보다 덜 중요하다는 것을 반영하기 위해 wi,hi 값에 루트를 씌웠다고 한다.
hat이 붙은 건, predict box의 좌표이다.
2. Confidence loss
λnoobj : 객체를 포함하지 않는 cell에 가중치를 두는 파라미터, 논문에서는 0.5로 설정 (5보다 훨씬 작으므로 객체가 없는 cell의 영향력을 줄임)
1 noobj i,j : 1 obj i,j와 반대로, i번째 grid cell의 j번째 bbox가 객체를 예측하도록 할당 받지 못하면 0, 아니면 1
Ci : 객체가 포함되어 있을 경우 1, 아니면 0
hat Ci : 예측한 bbox의 confidence score
3. classification loss
pi(c) : 실제 class probabilities
hat pi(c) : 예측한 clas probabilities
Limitations of YOLO
•이미지를 단순히 SxS로 나누고 각 grid에 대해서만 처리하였다.
= 작은 object들이 한 grid안에 여러 개 나타난다면 잘 처리하기 힘듦
= 공간적 제약
•주된 한계점 : incorrcet localization !
하지만 이런 한계점들은 YOLO의 버전이 올라가면서 많이 고쳐졌다고 한다.
Result
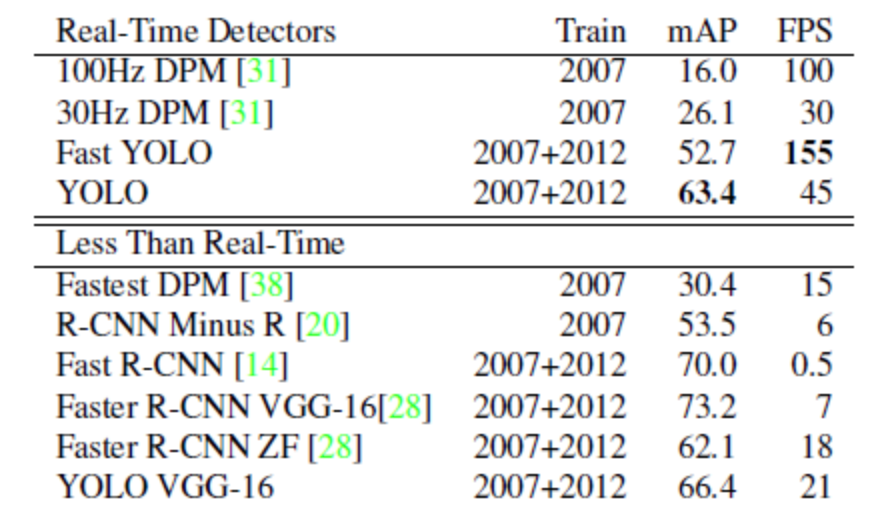
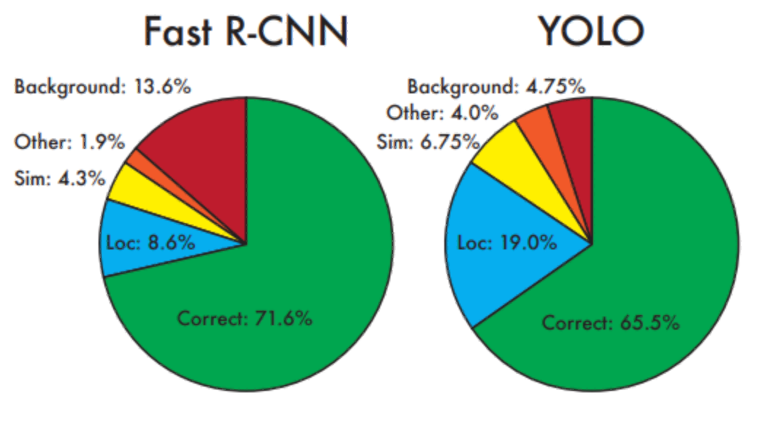
의의
1. 정확도와 mAP간 trade-off
2. background error가 적은 편
'AI 논문 공부' 카테고리의 다른 글
| ViT 논문 리뷰 (AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE) (0) | 2023.03.27 |
|---|---|
| Attention Is All You Need(2017) 논문 리뷰 (0) | 2023.03.16 |
| FPN : Feature Pyramid Net 논문 리뷰 (0) | 2023.02.06 |
| R-CNN, Fast R-CNN, Faster R-CNN 논문 리뷰 (1) | 2023.01.27 |
| Deformable Convolutional Network (DCN) 논문 리뷰 (0) | 2023.01.13 |