
cnn과 다르게 주어지는 입력 자체가 sequential하다는 특징을 가진다.
sequential data란? 말, 동영상, 연속적인 모션 등등을 말한다.
그렇다면 이러한 데이터가 처리하기 어려운 이유는? 받아 들여야하는 입력의 차원을 알 수 없다!
-> 그래서 CNN을 사용할 수 없다.(입력의 차원을 모르기 때문에)
-> 말을 할 때, 듣는 사람은 그 말이 언제 끝날지를 모른다는 것을 생각하면 이해할 수 있을 것이다.
1. sequential model
naive sequential model
(가장 기본적인 모델)
-> 어떤 입력이 들어왔을 때, 다음엔 어떤 입력이 들어올 지 예측하는 모델
-> 입력이 쌓일수록 고려해야할 과거의 데이터들이 계속 증가함
-> fix the past timespan : 과거의 몇개의 데이터에만 dependent
markov model
-> 바로 직전의 data에만 dependent
-> 내일이 수능이라면, 전날 공부한 data에만 영향을 받을거야!
-> joint distribution 표현이 용이하지만, 과거의 데이터를 많이 버린다는 단점
latent autoregressive model
input 과 output 사이에 hidden state가 있고, 이 hidden state는 과거의 정보를 요약해서 가지고 있다.
-> 다음 step은 직전 state(=hidden state)에만 영향을 받는다.
2. RNN(Recurrent Neural Network)
특이점 : 자기 자신으로 돌아오는 구조가 존재!
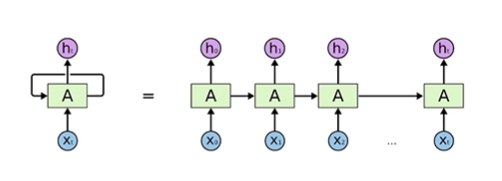
= 입력이 굉장히 많은 fully - connected layer와 동일하다고 볼 수 있다.
- short term dependencies 문제
과거의 정보를 모두 취합해서 예측해야하는데 그렇게 할 수 없다는 문제 (=long term dependency를 잡지 못함)
- RNN 학습이 어려운 이유
rnn을 시간 순으로 풀면, 엄청나게 큰 네트워크가 된다.
활성화 함수로 시그모이드를 적용하면 정보가 계속 스쿼싱 되면서 정보가 사라지게 되고,
렐루를 사용하면 정보가 엄청 커져서 네트워크가 폭발해버린다! (그래서 렐루는 특히 잘 사용하지 않는다)
-> LSTM 등장
3. LSTM
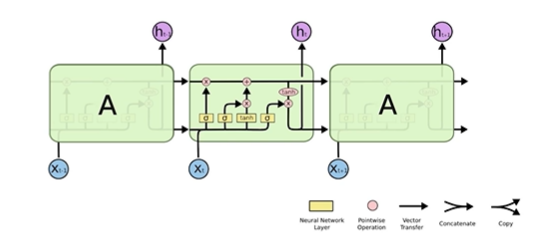
X는 input이다.
H는 output이고, hidden state이다!
왼쪽면에서, 왼쪽 상단의 입력은 previous cell state 이고, 하단의 입력은 previous output(=hidden state).
결국 이 왼쪽면에서 들어오는 것은 과거의 데이터에 대한 요약 정보이다.
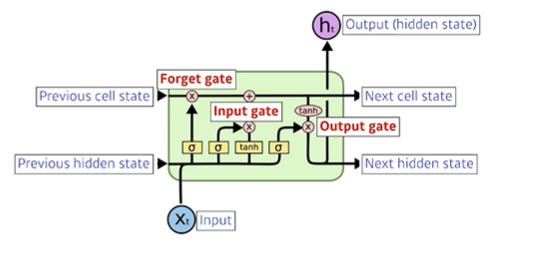
LSTM 구조
LSTM은 gate 위주로 이해를 하면 좋다.
LSTM의 core idea
내부에서 내부로 흐르는 입출력은 컨베이어 벨트와 같다!
그리고, 해당 컨베이어 벨트에 실려가는 정보를 알맞게 수정하는 것이 gate!
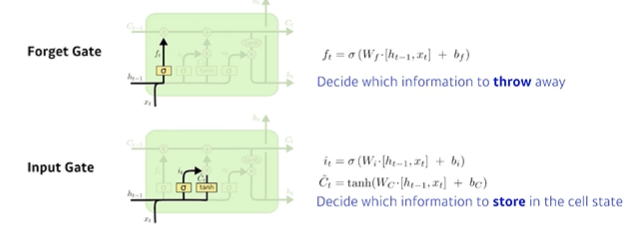
1. forget gate
어떤 정보를 버릴 것인지 결정, 이전 출력과 현재 입력을 통해 결정
2. input gate
현재 입력이 들어왔는데, 이 정보 중 어떤 정보를 골라서 컨베이어 벨트에 올릴 지 결정
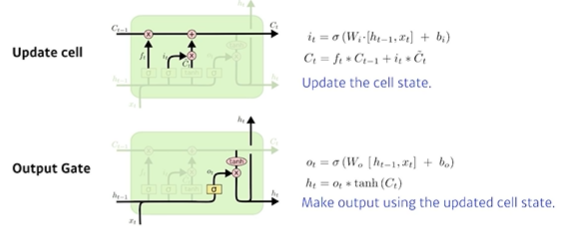
3. update cell
어느 값을 쓸지 버릴지 정해서 새로운 cell state를 update
4. output gate
어떤 값을 밖으로 내보낼 지 결정하는 gate
4. GRU(gated recurrent unit)
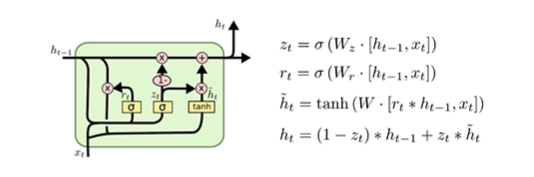
GRU구조
2개의 gate만 존재
hidden state가 곧 output이고, cell state가 없다!
LSTM보다 GRU 활용할 때 성능이 더 향상되는 경우 존재! (파라미터가 더 적으므로!)
5. 요즘엔 RNN보다 transformer가 더 대세라고 한다
'AI' 카테고리의 다른 글
| RNN 첫걸음 (0) | 2022.09.28 |
|---|---|
| CNN 첫걸음 (0) | 2022.09.28 |
| 딥러닝 기초 - CNN 간단 정리 (2) | 2022.09.28 |
| Regularization 간단 정리 (0) | 2022.09.28 |
| Gradient Descent Methods (0) | 2022.09.28 |