
convolution 작동 방법
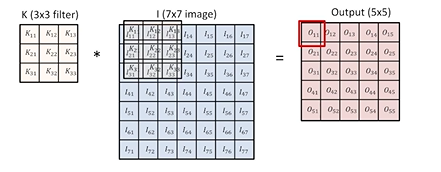
3 x 3필터를 7 x 7이미지에 적용하면, 5 x 5짜리 아웃풋이 나온다.
=도장을 찍어서 매칭되는 좌표의 값을 곱한 뒤 하나로 더하면 됨!
주로 3차원의 RGB 이미지를 다룬다.
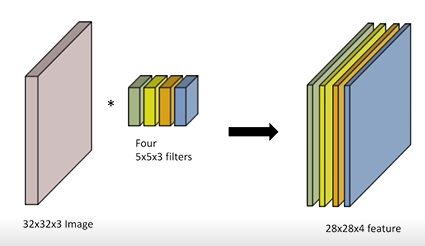
위 사진에서 차원이 하나 더 추가된 것을 알 수 있다.
필터를 한번 거치고 나면, 비선형 activation function 적용이 필요하다!(ex. ReLU)
CNN은 convolution layer, pooling layer, fully-connected layer로 이루어져 있다.
- convolution and pooling layer는 feature extraction의 역할을 함 (=이미지에서 유용한 정보를 뽑아주는 것)
- full-connenced layer는 decision making의 역할을 함(ex. classification)
최근에는 뒷단의 fully-connected layer가 최소화되는 추세이다
-> 모델의 파라미터 수에 dependent하기 때문
-> 파라미터 수가 증가할 수록, 학습이 어렵고 일반화 성능이 떨어짐
=> 결국 CNN은 모델을 deep하게, 그리고 파라미터 수를 줄이는 방향으로 발전해나감
stride
커널(컨볼루션 필터)을 얼마나 자주 찍을지를 말하는 정도 (= 커널을 몇칸씩 움직일 것인지)
stride 1은 필터를 한칸씩 이동, 2는 두 칸씩 이동
padding
바운더리 정보를 원할 때, 커널이 밖으로 삐져나오는 상황에서 빈 곳에 값을 채워주는(=덧대주는) 역할
zero padding이면 인풋의 바깥쪽에 0을 덧대고, 그 상태에서 convolution을 하면 아웃풋과 인풋의 차원이 같아진다!
인풋이 동일해도, 필터의 크기에 따라 패딩은 변한다!
아래 짤은 커널 크기는 3 x 3이고, stride가 1이고 padding이 존재한다!
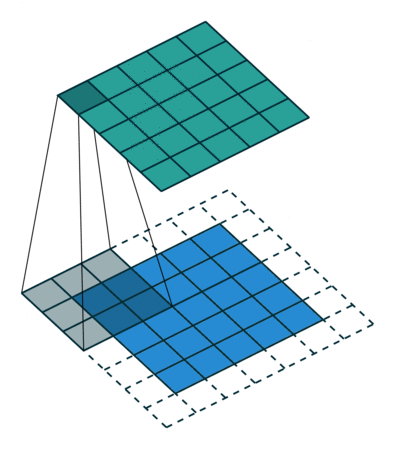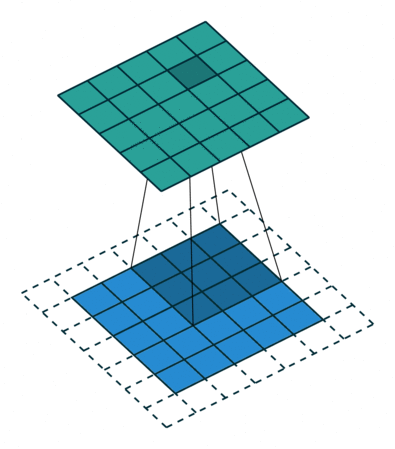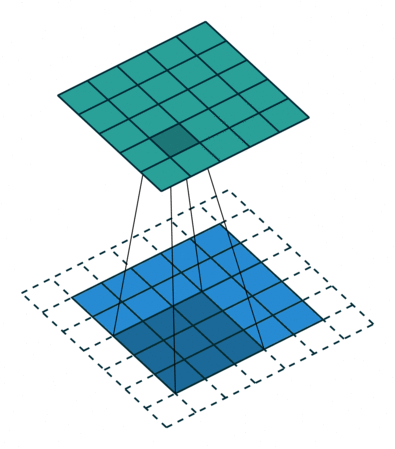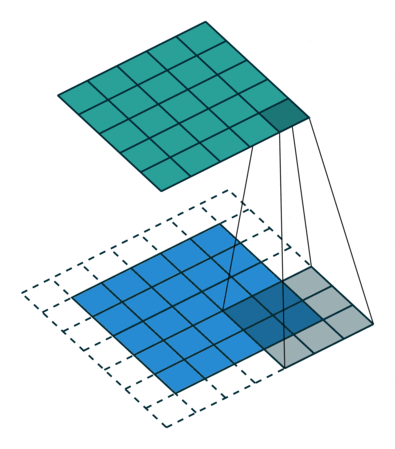
파라미터 수 계산
가정 : padding(1), Stride(1), 3 x 3 kernel (물론 패딩이나 스트라이드는 파라미터 수와 무관)
(오직 커널과 채널 수에 영향을 받음)
Input = weight x height x channel (40 x 50 x 128)
Output = 40 x 50 x 64 일때
자동적으로, 커널의 채널의 크기는 내가 가진 인풋의 채널과 동일해진다!
그래서 커널이 3 x 3 x 128이 되고, 그러면 convolution을 진행했을 때 40 x 50 x 1이 하나 나온다!
아웃풋은 채널이 64개 이므로,
총 파라미터의 수는 3*3*128*64! (= 커널 크기 x 인풋의 Channel x 아웃풋의 Channel)
나중가서는 파라미터 수에 대한 '감'을 익히는 것도 중요하다
AlexNet을 통한 파라미터 수 계산 exercise
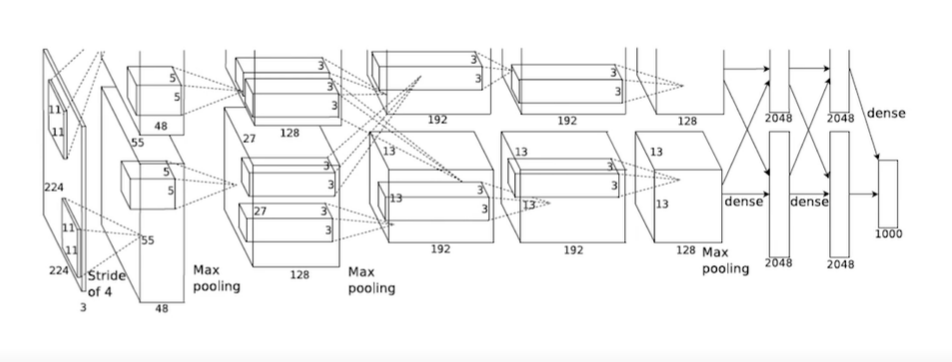
인풋 : 224 x 224 x 3
첫번째 필터 : 11 x 11 x 3 (stride 4)
아웃풋 : 55 x 55 x 48이 2개
파라미터 수 : 11 x 11 (필터 크기) x 3(인풋 채널의 크기) x 48 (아웃풋 채널) x 2
(원래 의도한 아웃풋 채널은 96인데 gpu 메모리 때문에 48 x 2로 분할)
-> 첫번째 레이어로 넘어가는데 필요한 파라미터 수 : 35k(약 35000)
인풋 : 55 x 55 x 48
필터 : 5 x 5 x 48
아웃풋 : 27 x 27 x 128
두번째 convolution layer에 필요한 파라미터 수: 5 x 5 x 48 x 128 x 2
-> 약 307K (약 31만)
인풋 : 27 x 27 x 128
필터 : 3 x 3 x 128
아웃풋 : 13 x 13 x 192
세번째 convolution layer에 필요한 파라미터 수: 3 x 3 x 128 x 2 x 192 x 2
(위에서 강조한 부분은, 두개의 레이어가 InterChange 되는 것을 의미)
-> 약 884K (약 88만)
등과 같은 방식으로 진행된다.
dense layer(MLP or fully-connected layer)부터는 차원이,
인풋의 파라미터 개수와 아웃풋의 파라미터 개수를 곱한 것이 된다.
인풋 : 13 x 13 x 128
근데 인풋이 2개 존재하니까 x2
아웃풋은 2048인데 아웃풋 역시 2개니까 x2
=> 13 x 13 x 128 x 2 x 2048 x 2 = 177M
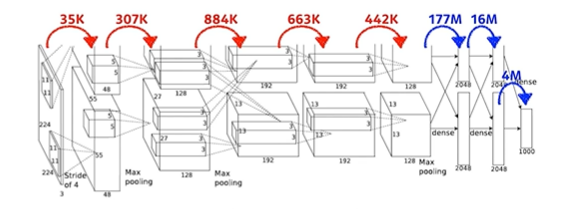
파라미터 수들
빨간색 부분은 convolution layer고, 파란색은 dense layer이다.
딱 봐도, dense layer에서 파라미터가 엄청나게 증가하는 것을 확인할 수 있다.
왜 그럴까? convolution operator는 일종의 shared parameter이기 때문
= 같은 커널이 이미지 구석구석에 동일하게 적용되기 때문
-> 네트워크가 발전되기 위해선 파라미터 수가 줄어야 하므로, 앞서 말했듯 앞단을 깊게 쌓고 뒷단을 최소화하는 추세 등장
1 x 1 convolution

why??
for dimension reduction (차원은 유지하되, 채널은 감소)
-> 레이어를 깊게 쌓으면서도 파라미터를 감소할 수 있도록 해줌!
'AI' 카테고리의 다른 글
| CNN 첫걸음 (0) | 2022.09.28 |
|---|---|
| 딥러닝 기초 - RNN 간단 정리 (0) | 2022.09.28 |
| Regularization 간단 정리 (0) | 2022.09.28 |
| Gradient Descent Methods (0) | 2022.09.28 |
| 딥러닝 최적화 용어 간단 정리 (0) | 2022.09.28 |