AlexNet을 개략적으로 설명하자면, 딥러닝과 CNN의 주목을 이끌었고, 이에 따라 CNN 구조의 GPU 구현과 dropout 적용이 보편화되는 경향을 가져왔다.
목차
1. DataSet
2. Architecture
3. Reduce Overfitting
4. 학습 세부사항
5. 결과
1. DataSet

2. Architecture
2-1. 활성화 함수 ReLU 사용
backpropagation을 했을 때, vanishing Gradient문제 X, 속도 향상

(vanishing Gradient란? Sigmoid에서 입력값들이 그래프 가운데에서 멀어질 경우, 미분값이 작아져 뒤에 있는 뉴런들이 잘 학습이 되지 않는 문제)
2-2. overlapping pooling
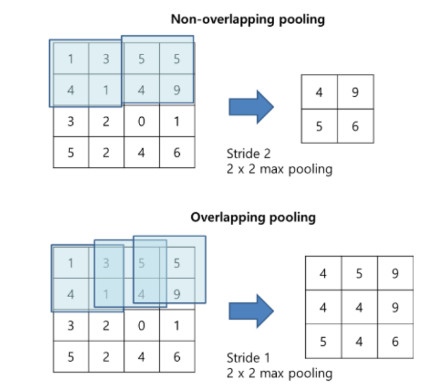
2-3. Multiple GPUs
이 역시 top-1, top-5 에러율 감소
2-4. local response normalization
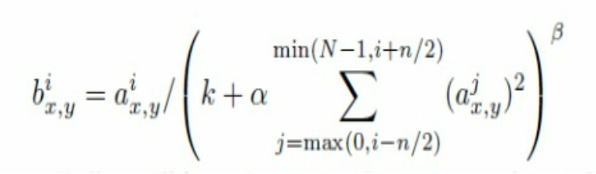
ReLu는 양수에서는 입력값을 그대로 사용 -> conv나 pooling 시 매우 높은 픽셀값이 주변에 영향
-> 이를 방지하기 위해 normalization (ReLU 뒤에 적용)
-> 그러나 요즘은 batch normalization이란 것을 사용한다고 한다.
(주변 필터의 결과값을 이용해 정규화)
(a = 이미지상 특정 x,y 위치에 있는 i번째 conv filter가 적용된 결과값)
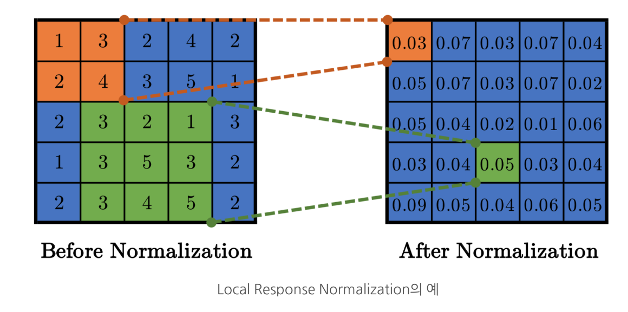
2-5. overall
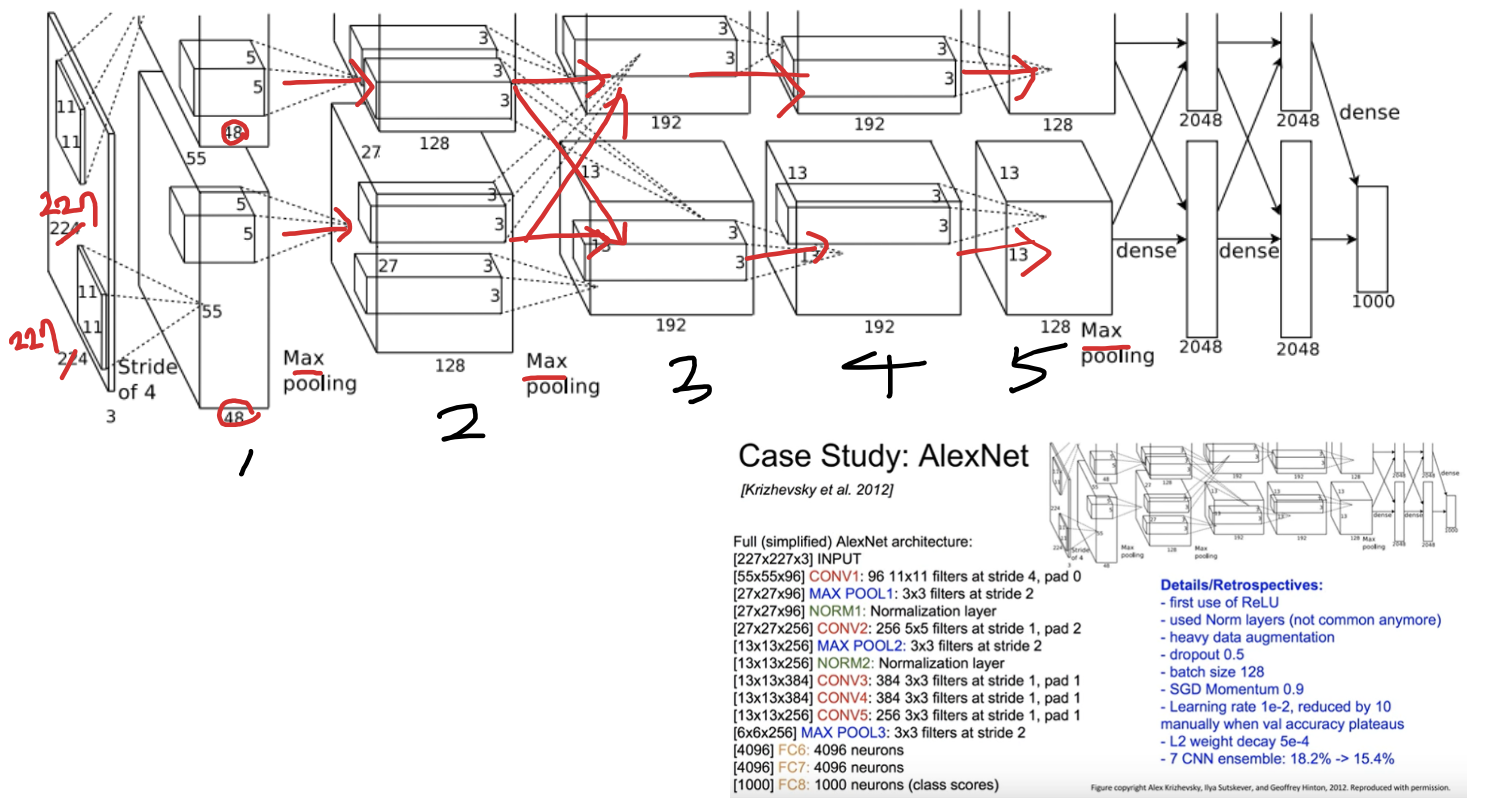
3. Reduce Overfitting
3-1. Data Augmentation
- 데이터를 다양하게 형성, cpu에서 실행하므로 부담이 없다.
3-1-1. mirroring
using label-preserving transformation (라벨의 특성은 유지한 채 변환)
논문에서는 수평반전 사용

3-1-2. Random Crops
256x256에서 227x227 크기로 무작위 추출 -> 데이터 양 2048배 증가
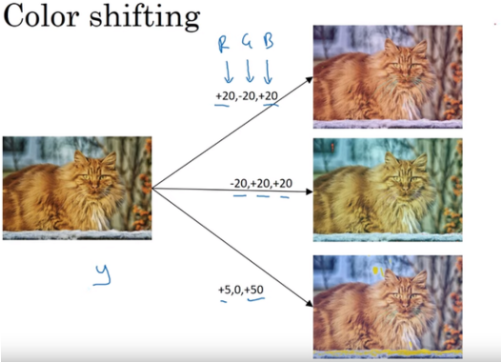
3-1-3. PCA Color Augmentation
데이터 셋의 색상 변경(이미지의 특성은 유지)
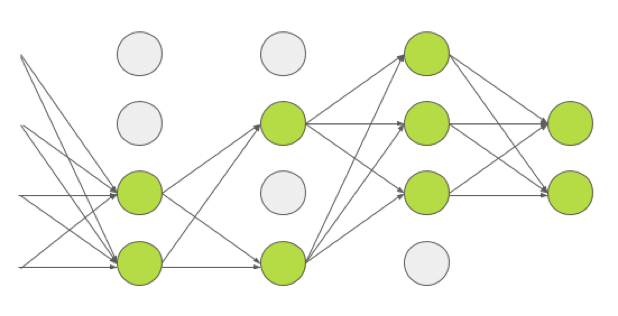
3-2. Drop out
4. Details of learning

5. Result

'AI 논문 공부' 카테고리의 다른 글
| R-CNN, Fast R-CNN, Faster R-CNN 논문 리뷰 (1) | 2023.01.27 |
|---|---|
| Deformable Convolutional Network (DCN) 논문 리뷰 (0) | 2023.01.13 |
| resnet 논문 리뷰 (1) | 2023.01.07 |
| GoogleNet 논문 리뷰 (0) | 2022.12.30 |
| vggNet 논문 리뷰 (0) | 2022.11.30 |