베이즈 정리란? 데이터가 새로 추가될 때 마다 정보를 업데이트
베이즈 통계학을 알기 위해서는 조건부 확률을 알아야한다
조건부 확률
P(A n B) = P(B)P(A|B)
P(A|B)는 B가 일어난 상황에서 A가 발생할 확률을 의미
베이즈 정리는 조건부 확률을 이용하여 정보를 갱신하는 방법을 알려준다
=P(B|A) <=> P(A n B) / P(A) <=> P(B) x P(A|B) / P(A)
=A라는 새로운 정보가 주어졌을 때 P(B)로부터 P(B|A)를 계산하는 방법을 제공

- evidence는 데이터 전체의 분포를 의미.
베이즈 정리 예제
코로나 바이러스의 발병률은 10%, 실제로 걸렸을 때 검진될 확률을 99%, 실제로 걸리지 않았을 때 오검진될 확률은 1% 이고,
어떤 사람이 질병에 걸렸다고 검진 결과가 나왔을 때 정말로 코로나 바이러스에 걸렸을 확률을?
풀이
사전 확률 P(θ) = 0.1
가능도 P(D|θ) = 0.99, P(D|¬θ) = 0.01 (※ P(D|¬θ)가 커질 수록 정확도는 낮아진다!)
Evidence =Σ ( P(D|θ) x P(θ) ) = 0.99 x 0.1 + 0.01 x 0.9 = 0.108
=> P(θ|D) = 사전확률 x 가능도 / Evidence = 0.1 x 0.99 / 0.108 ≈ 0.916
조건부 확률의 시각화
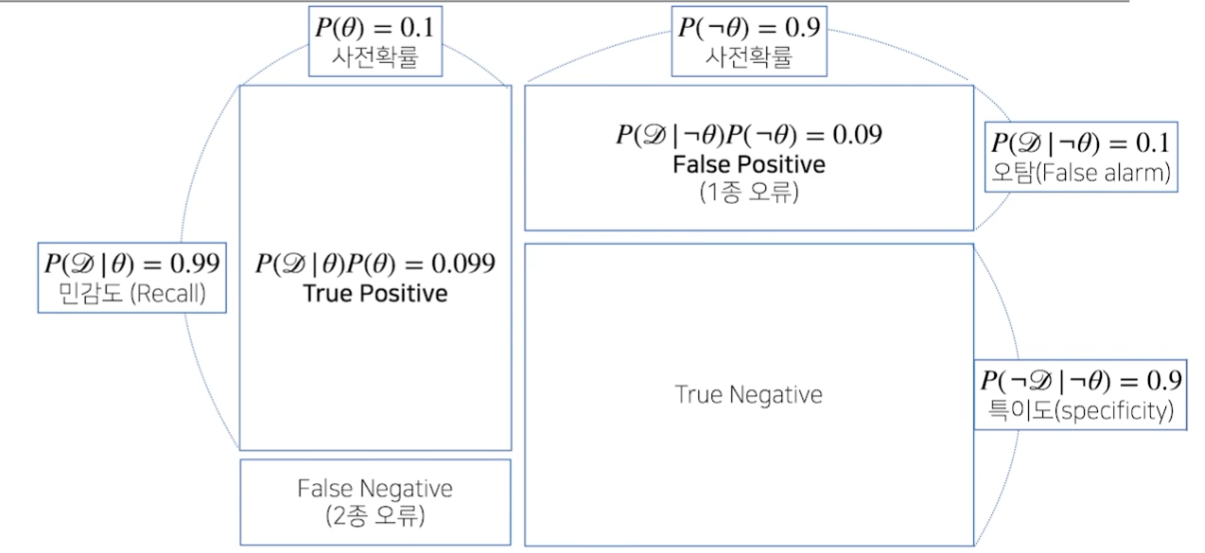
실제 병에 걸렸을 때, 제대로 검진한 경우 = True Positive
실제 병에 걸렸을 때, 검진하지 못한 경우 = False Negative (2종 오류) -> 의료 분야에서 이 경우를 정말 조심해야 한다!
병에 걸리지 않았을 때, 걸렸다고 검진한 경우 = False Positive (1종 오류)
병에 걸리지 않았을 때, 검진 되지 않은 경우 = True Negative
베이즈 정리를 통한 정보의 갱신
새로운 데이터가 들어왔을 때, 앞서 계산한 사후확률을 사전확률로 사용하여 갱신된 사후확률을 계산할 수 있다!
앞선 예제를 활용
앞서 코로나 바이러스 판정을 받은 사람이 두번째 검진을 받았을 때도 양성이 나왔을 때, 진짜 코로나 바이러스에 걸렸을 확률은? ( ※ 위 예제와 달리, 오검진률 (=1종 오류)을 10%라 가정)

갱신된 Evidence는 0.99 x 0.524 + 0.1 x .476 ≈ 0.566
갱신된 사후 확률 = 0.524 x 0.99 / 0.566 ≈ 0.917
검사를 하면 할수록 정밀도가 올라감을 알 수 있다!
유의점
조건부 확률은 유용한 통계적 해석을 제공하지만, 인과관계를 추론할 때 함부로 사용해서는 안된다!
(데이터가 아무리 많아도 안된다, 그냥 불가능!)
인과관계
- 데이터 분포의 변화에 강건한 예측모형을 만들 때 필요 => 데이터 분포가 달라져도 예측 정확도가 크게 달라지지 않는다
그러나, 높은 예측 정확도를 보장하기는 어렵다.
인과관계를 알아내기 위해서는 중첩요인의 효과를 제거하고 원인에 해당하는 변수만의 인과관계를 계산해야한다.
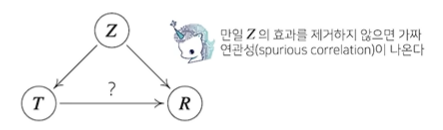
Z가 바로 중첩요인이다.
키와 지능의 상관관계를 따져보자. 우리가 아는 상식선에서 키와 지능은 전혀 연관이 없다는 것을 알고 있다.
하지만, 인과관계를 따져보면 키와 지능은 연관이 있다는 결과가 나올 것이다.
이유가 뭘까? 바로 "나이" 라는 중첩요인을 배제하지 않았기 때문이다.
0세부터 성인이 될 때 까지 키는 계속 자라며, 사회화 및 학습이 이루어질 수록 지능은 상승한다.
이러한 이유로 키가 클수록 지능이 높다라는 가짜 연관성이 나오는 것이다!
중첩요인의 제거는 필수적이다!
동일한 나이의 실험군을 이용하면 지능과 키는 상관이 없다는 결과가 나올 것이다
중첩 제거는 do(T=a)라는 조정(invervention)효과를 통해 Z의 개입을 제거할 수 있다.
